Oups ! Une erreur s'est produite lors de l'envoi du formulaire.
Comment utiliser l'IA pour les révisions de code : Automatiser le feedback des PR sans manquer de bugs
Les revues de code manuelles détectent les bugs mais accaparent le temps de votre équipe. Découvrez comment l'IA automatise les retours sur les PR — des failles de sécurité aux problèmes de style — pour que vous livriez plus rapidement sans goulot d'étranglement. Essayez-le gratuitement.
Qu'est-ce que la revue de code et pourquoi elle est toujours essentielle
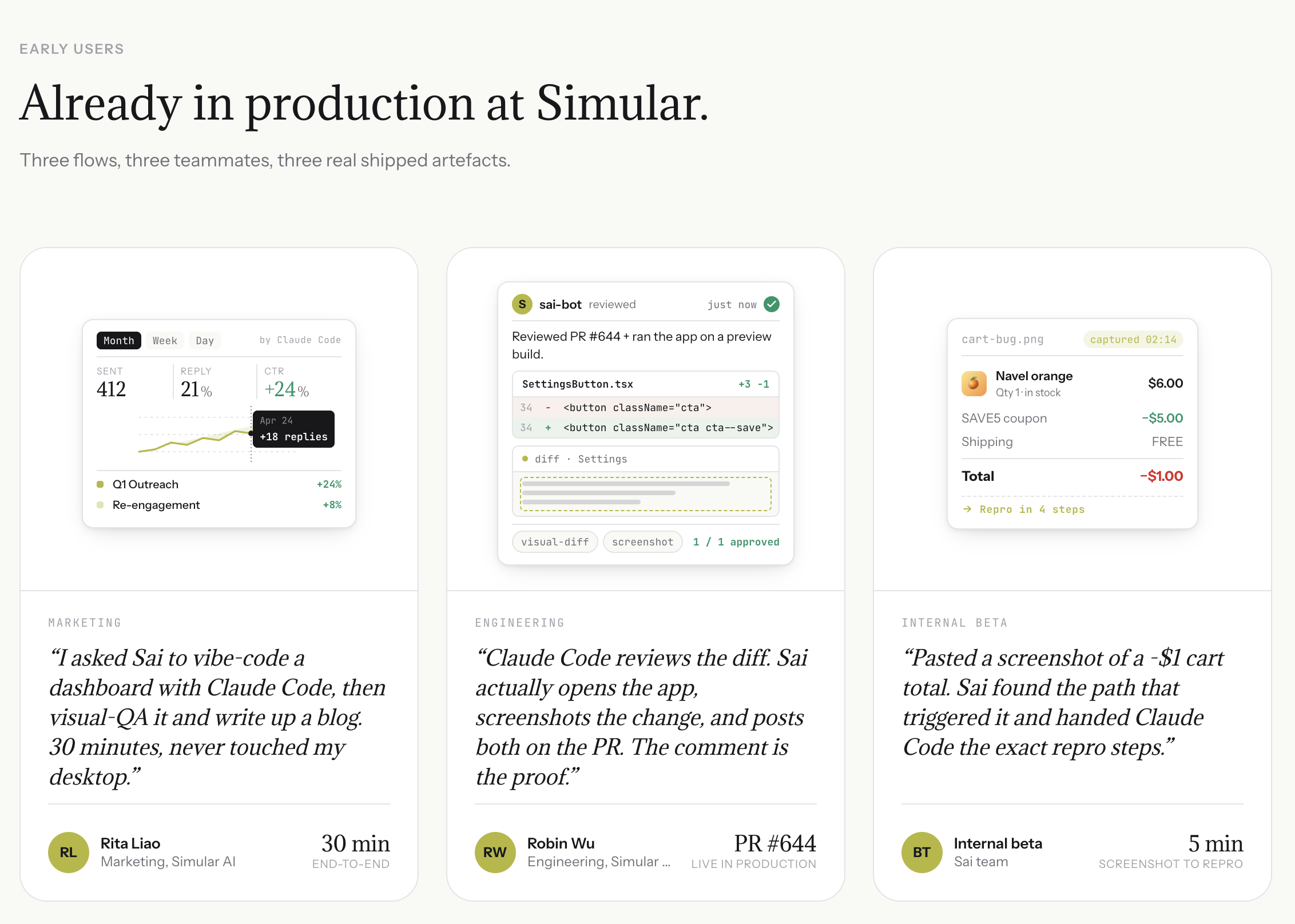
Ouvrez Sai et dites "Réviser la PR #247 dans notre dépôt frontend."
Sai récupère le diff, exécute l'analyse de code avec Claude Code, teste les parcours utilisateur affectés sur l'environnement de staging, et publie une révision complète avec des commentaires de code en ligne et des preuves comportementales (captures d'écran, étapes de reproduction, erreurs de console).
Configure la révision automatisée en disant : « Surveille la branche principale de notre dépôt d'API et examine chaque PR automatiquement. »
Sai surveille les nouvelles PR, exécute le pipeline de révision complet (analyse de code + tests comportementaux) et rédige une révision pour votre approbation avant de la publier.
Créez un calendrier de révision en disant à Sai : « Chaque matin, vérifie les PR ouvertes dans nos trois dépôts principaux et envoie-moi un résumé avec les priorités de révision. »
Sai trie les PR par niveau de risque (les modifications de sécurité, les migrations de base de données et la logique d'authentification sont signalées comme étant hautement prioritaires), afin que vous examiniez les plus critiques en premier.
Qu'est-ce que la revue de code et pourquoi elle est toujours essentielle
La revue de code est l'examen systématique du code source par une personne autre que l'auteur original. L'objectif est de détecter les bugs, d'améliorer la qualité du code, de partager les connaissances au sein de l'équipe et de maintenir la cohérence de la base de code.
Ces fondamentaux n'ont pas changé. Ce qui a changé, c'est le volume et la nature du code examiné.
Les assistants de codage basés sur l'IA génèrent désormais 30 à 60 % du code dans de nombreuses équipes. Les développeurs utilisant GitHub Copilot acceptent les suggestions 30 % du temps, selon les propres recherches de GitHub. Cela signifie que les relecteurs évaluent de plus en plus du code qu'ils n'ont pas vu être écrit, par un auteur (IA) qui ne peut pas expliquer son raisonnement lorsqu'on le lui demande.
Trois problèmes émergent :
Surcharge de volume. Plus de code généré plus rapidement signifie plus de PR à examiner, sans augmentation de la capacité des relecteurs.
Correction trompeuse. Le code généré par l'IA semble souvent syntaxiquement parfait mais contient des erreurs logiques subtiles, des hypothèses codées en dur ou des cas limites manquants.
Cécité contextuelle. L'IA qui a écrit le code ne connaît pas vos règles métier, vos contraintes de déploiement, ni que la fonction qu'elle vient de générer duplique la logique d'un autre service.
La revue de code manuelle seule ne peut pas suivre le rythme. Mais remplacer entièrement les relecteurs humains par des outils d'IA crée un risque différent : des outils qui détectent les erreurs au niveau des motifs mais manquent le comportement au niveau de l'application. La solution est la superposition — attribuer les bonnes tâches de relecture au bon relecteur (humain, outil ou agent).
La checklist de revue de code indispensable à chaque équipe
Avant d'introduire des outils d'IA, les équipes ont besoin d'un cadre clair pour ce qu'une revue de code doit couvrir. La plupart des checklists se concentrent sur le style et la syntaxe. Une checklist complète comprend quatre niveaux :
Review Item
What to Check
Best Owner
Formatting and style
Indentation, naming conventions, import order, line length
Authorization bypass, privilege escalation, data exposure in new endpoints
AI Review Tool + Human
Test coverage
New functions have tests, edge cases covered, mocks are realistic
AI Review Tool + Human
Behavior verification
UI renders correctly, user flows work end-to-end, calculations match specs
AI Agent
Visual regression
Layout shifts, broken responsive design, missing elements on staging
AI Agent
Architecture and design
Module boundaries, dependency direction, API contract consistency
Human
Product intent
Does this solve the right problem? Should we build this at all?
Human
Cette checklist est délibérément structurée comme une progression. Chaque niveau s'appuie sur le précédent. Un linter gère le formatage afin que les humains puissent se concentrer sur la logique. Un outil de revue d'IA gère la détection des motifs répétitifs afin que les humains puissent se concentrer sur l'architecture. Un agent IA gère la vérification du comportement afin que les humains puissent se concentrer sur les décisions produit.
Comment fonctionnent les revues de code manuelles (et où elles montrent leurs limites)
Le processus manuel de revue par les pairs dans la plupart des équipes suit un schéma prévisible :
Le développeur ouvre une pull request avec une description des modifications.
Un ou deux relecteurs sont désignés (ou se portent volontaires).
Les relecteurs lisent le diff, fichier par fichier.
Les relecteurs laissent des commentaires en ligne sur des lignes spécifiques.
Le développeur répond aux commentaires, apporte des modifications, pousse les mises à jour.
Le relecteur approuve. La PR est fusionnée.
Ce processus fonctionne bien pour les petites équipes avec une vélocité modérée. Il montre ses limites à grande échelle pour trois raisons :
Latence de la revue. Le temps médian entre l'ouverture d'une PR et le premier commentaire de revue est de 24 heures dans la plupart des entreprises. Pour les PR volumineuses (plus de 500 lignes), cela peut prendre 48 à 72 heures. Cette latence s'aggrave lorsque les relecteurs demandent des modifications et que le cycle se répète.
Profondeur incohérente. Sous la pression du temps, les relecteurs survolent. Une étude de 2023 de Microsoft Research a révélé que les relecteurs consacrent en moyenne 10 minutes par revue, quelle que soit la taille de la PR — ce qui signifie qu'une PR de 50 lignes reçoit la même attention qu'une PR de 500 lignes.
Silos de connaissances. Quand une seule personne comprend un sous-système, elle devient le relecteur goulot d'étranglement. Si elle est en vacances ou surchargée, les PR s'accumulent.
Aucun de ces problèmes n'est résolu en disant aux développeurs de "revoir plus attentivement". Ils nécessitent des solutions structurelles — des outils et des agents qui gèrent les parties révisables par machine afin que les humains se concentrent sur les parties que seuls les humains peuvent évaluer.
Outils de revue de code : Linters, SAST et analyse statique
La première couche d'automatisation est l'outillage déterministe. Ce ne sont pas des IA — ils appliquent des règles fixes au code.
Les linters (ESLint, Pylint, Rubocop, Clippy) imposent une cohérence de style et détectent les erreurs courantes. Ils sont rapides, prévisibles et gratuits. Chaque équipe devrait avoir des linters fonctionnant en CI.
Les outils d'analyse statique de la sécurité des applications (SAST) (SonarQube, Semgrep, Snyk Code, CodeQL) analysent le code à la recherche de schémas de vulnérabilité connus — injection SQL, XSS, désérialisation non sécurisée, secrets codés en dur. Ils opèrent sur l'AST (arbre syntaxique abstrait) et appliquent la correspondance de motifs par rapport à des bases de données de vulnérabilités connues.
Les vérificateurs de types (TypeScript, mypy, Flow) détectent les incompatibilités de types au moment de la compilation qui autrement se manifesteraient comme des erreurs d'exécution en production.
Ces outils sont essentiels mais limités. Ils détectent ce qui peut être exprimé sous forme de règle. Ils ne peuvent pas évaluer :
Si la logique d'une fonction correspond à l'exigence produit pour laquelle elle a été conçue
Si un nouveau point de terminaison d'API gère correctement l'autorisation dans tous les cas limites
Si un changement d'interface utilisateur introduit une régression visuelle
Si une requête de base de données aura des performances acceptables à l'échelle de la production
Pour ces évaluations, vous avez besoin d'IA.
Outils d'examen de code par IA : Comment ils fonctionnent et ce qu'ils détectent
Les outils d'examen de code par IA se situent entre l'analyse statique et les relecteurs humains. Ils utilisent de grands modèles linguistiques pour comprendre la sémantique du code — pas seulement les motifs, mais le sens.
Voici comment les principaux outils se comparent :
Tool
Type
Pricing
Platforms
Standout Feature
CodeRabbit
AI review bot
Free (open source) / $12/seat/mo
GitHub, GitLab, Bitbucket
Line-by-line contextual review with learning from past PRs
Greptile
AI review bot
Free (beta) / from $40/dev/mo
GitHub, GitLab
Full codebase indexing for cross-file context
GitHub Copilot
IDE assistant + review
$10/mo Individual / $19/mo Business
GitHub only
Native GitHub integration, code review in PR interface
Graphite
PR management + AI review
Free / Team $25/seat/mo
GitHub
Stacked PRs with AI-assisted review and merge queue
Qodo (CodiumAI)
AI review + test generation
Free / Teams from $19/seat/mo
GitHub, GitLab, VS Code, JetBrains
Auto-generates tests alongside review suggestions
Claude Code (/review)
AI coding agent with review
Usage-based (Claude API)
Terminal, any Git repo
Deep code understanding with subagent architecture
Sai
AI agent with behavior testing
Free / Pro $20/mo
macOS, Windows (cloud desktop)
Reviews code AND tests application behavior on staging
Comment fonctionnent les outils d'examen de code par IA. Lorsqu'une PR est ouverte, l'outil extrait le diff (et souvent le contexte du fichier environnant), l'envoie à un LLM et génère des commentaires en ligne. Les meilleurs outils analysent également le contexte complet du dépôt — comprenant comment la fonction modifiée interagit avec d'autres parties de la base de code.
Ce qu'ils détectent et que les linters manquent :
Erreurs de logique. "Cette fonction retourne prématurément à la ligne 47, donc le code de nettoyage à la ligne 52 ne s'exécute jamais."
Cas limites manquants. "Ce gestionnaire ne prend pas en compte les tableaux vides, ce qui provoquera une erreur de type (TypeError) en production."
Problèmes de sécurité contextuels. "Ce point de terminaison d'API accepte les entrées utilisateur mais ne valide pas le champ de rôle, permettant une élévation de privilèges."
Problèmes de performance. "Cette requête de base de données à l'intérieur d'une boucle générera N+1 requêtes. Envisagez le traitement par lots."
Lacunes de documentation. "Cette fonction publique n'a pas de JSDoc et les noms des paramètres sont ambigus."
Ce que les outils d'examen par IA manquent encore. Chaque outil du tableau ci-dessus fonctionne sur la même entrée : le diff du code et le contexte du fichier environnant. Ils lisent le code. Ils n'exécutent pas le code. Cela crée un angle mort fondamental.
Comment automatiser la revue de code avec un agent IA
Un agent IA ne se contente pas de lire le diff. Il opère un ordinateur. Il peut ouvrir un navigateur, naviguer vers votre environnement de staging, interagir avec l'interface utilisateur, prendre des captures d'écran et vérifier que la modification du code produit le comportement attendu.
Voici la différence en pratique :
Review Capability
Manual Reviewer
Linter / SAST
AI Review Tool
AI Agent (Sai)
Reads the diff
Yes
Yes
Yes
Yes
Understands full repo context
Partial
No
Yes
Yes
Catches style violations
Inconsistent
Yes
Yes
Yes
Detects known vulnerability patterns
Sometimes
Yes
Yes
Yes
Finds logic errors
Yes (when focused)
No
Yes
Yes
Suggests performance improvements
Senior only
Limited
Yes
Yes
Runs the application
Sometimes
No
No
Yes
Tests user flows on staging
Rarely
No
No
Yes
Captures screenshots as evidence
No
No
No
Yes
Evaluates architecture decisions
Yes
No
Partial
Partial
Assesses product-level intent
Yes
No
No
No
Avec Sai, le processus de revue de code devient une boucle fermée :
La PR est ouverte. Sai détecte la nouvelle pull request.
Analyse du diff. Sai lit les fichiers modifiés et identifie les fonctionnalités affectées.
Collecte de contexte. Sai vérifie les problèmes connexes, les conversations précédentes et les journaux de déploiement.
Revue de code. Sai exécute la commande /review de Claude Code pour détecter les problèmes au niveau du code — erreurs de syntaxe, lacunes logiques, schémas de sécurité.
Test comportemental. Sai ouvre un navigateur, navigue vers le déploiement de staging et teste les parcours utilisateur affectés.
Collecte de preuves. Sai prend des captures d'écran, enregistre les étapes de reproduction et capture les erreurs de console.
Génération de rapport. Sai compile une revue avec des commentaires au niveau du code ET des preuves au niveau comportemental.
Commentaire de PR. Sai publie la revue complète sous forme de commentaire de PR avec les captures d'écran jointes.
L'idée clé : les étapes 1 à 4 sont ce que fait chaque outil de revue de code IA. Les étapes 5 à 8 sont ce que seul un agent IA ayant accès à un ordinateur peut faire. Pour une présentation détaillée de l'intégration de Claude Code qui alimente les étapes 3 et 4, consultez : Sai exécute désormais Claude Code.
Étape par étape : Mettre en place la revue de code assistée par IA avec Sai
Étape 1 — Connectez votre dépôt GitHub. Dans Sai, connectez votre compte GitHub. Sai accède à vos dépôts via l'API GitHub — lisant les PR, les diffs, les problèmes et les résultats CI/CD. Aucun code ne quitte votre infrastructure ; Sai lit les diffs via l'API de la même manière que toute application GitHub.
Étape 2 — Définissez votre périmètre de revue. Indiquez à Sai quels dépôts et branches surveiller. Exemple : "Revoyez toutes les PR ciblant la branche principale de notre dépôt frontend." Vous pouvez définir des déclencheurs de revue — chaque PR, uniquement les PR de plus de 100 lignes, uniquement les PR touchant des répertoires spécifiques, ou uniquement les PR provenant d'outils de codage IA.
Étape 3 — Définir les règles de révision de code. Définissez ce qui est important pour votre équipe. Sai les applique comme critères de révision :
Sécurité : Vérifier les secrets codés en dur, les schémas d'injection SQL, les entrées utilisateur non validées
Performance : Signaler les requêtes N+1, les boucles infinies, la pagination manquante
Tests : Exiger une couverture de test pour les nouvelles fonctions publiques
Architecture : Appliquer les limites de modules et les restrictions d'importation
Logique métier : Vérifier que les calculs correspondent aux exigences documentées
Étape 4 — Configurer la vérification comportementale. C'est ce qui distingue Sai de tous les autres outils. Indiquez à Sai l'URL de votre environnement de staging. Définissez les parcours utilisateur critiques à tester :
Parcours de commande : ajouter des articles, appliquer un coupon, vérifier le total, finaliser l'achat
Authentification : connexion, réinitialisation du mot de passe, expiration de session
Tableau de bord : les données se chargent correctement, les filtres fonctionnent, l'exportation génère des fichiers valides
Lorsqu'une PR modifie du code qui affecte ces parcours, Sai ne se contente pas de réviser le diff. Il ouvre un navigateur, exécute le parcours sur l'environnement de staging et capture des captures d'écran de chaque étape.
Étape 5 — Configurer les notifications. Choisissez où Sai publie les révisions : sous forme de commentaires de PR GitHub, de messages Slack, ou les deux. Configurez les niveaux d'urgence — les problèmes de sécurité critiques déclenchent des alertes Slack immédiates ; les suggestions de style sont publiées uniquement sous forme de commentaires de PR.
Étape 6 — Approuver et surveiller. Sai demande toujours une approbation avant de publier des commentaires de PR ou d'envoyer des messages. Vous examinez le commentaire brouillon, l'approuvez ou le modifiez, et Sai le publie. Avec le temps, vous pouvez configurer l'approbation automatique pour les constatations à faible risque (style, documentation) tout en maintenant l'approbation requise pour les constatations de sécurité et de logique.
Pour les équipes utilisant déjà Claude Code pour le développement, l'intégration est transparente — Sai exécute la commande /review de Claude Code dans le cadre de son pipeline d'analyse. Consultez le guide de configuration complet dans notre Tutoriel de révision de code Claude Code.
Stop doing repetitive tasks. Let Sai handle them for you.
Sai is your AI computer use agent — it operates your apps, automates your workflows, and gets work done while you focus on what matters.

.svg)


.svg)