
Agent S3:通过大规模扩展实现人机级计算机的使用
自从一年前在OSWorld上推出我们的第一个框架Agent S以来,我们的比例为20.6%,一直在计算机使用代理的前沿领域稳步向前迈进。特工S2将最新水平提高到48.8%,现在 代理 S3 将性能提升到 69.9%,接近人类水平的72%。
自从这项工作以来,Agent S继续快速前进。在 Simular 的最新公告中,Agent S 实现了 osWorld 成功率为 72.6%,超越了基准 72.36% 的人体基线。
代理 S3 直接建立在代理 S2 的基础上。通过简化框架和引入原生编码代理,我们将OSWorld的性能提高到62.6%,开创了新的技术水平。除此之外,Agent S3 还推出了第一个 计算机用途代理的大规模框架 通过 Behavior of-n (bbON)。BbON 不依赖单一代理运行,而是从多个部署中进行选择并选择最佳结果。这种方法可以实现可扩展的性能提升,将准确性从 62.6% 提高到 69.9%,并展示了代理框架如何仅通过扩展更多样化的代理运行即可改进。

全新最先进的、接近人类水平的性能
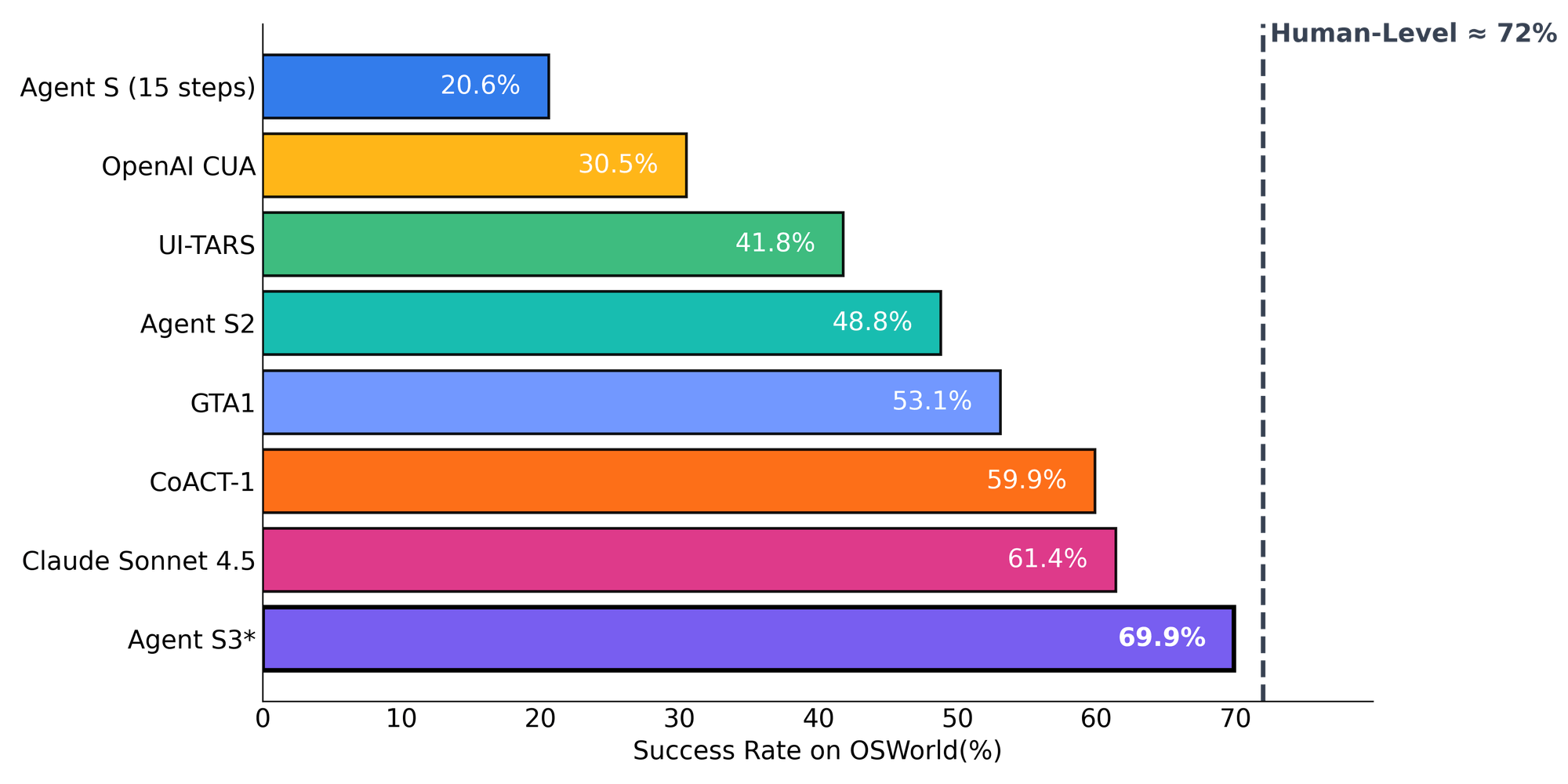
在OSWorld上,仅Agent S3在100步设置中就达到了62.6%,已经超过了之前的61.4%(Claude Sonnet 4.5)。随着Behavior Best-of-N的加入,性能进一步攀升至69.9%,使计算机使用代理的精度与人类水平的精度相差仅几个百分点(72%)。
为了实现跨环境的推广,Agent S3 在应用 Behavior Of-n 时也显示出很大的改进。在WindowsAgentArena上,通过从多次部署中进行选择,准确率从仅使用Agent S3的50.2%提高到56.6%。同样,在安卓世界上,性能从68.1%提高到71.6%。
CUA 瓶颈:长远任务的高方差

计算机使用代理(CUA)承诺未来软件可以自行运行,预订机票,填写表单和浏览应用程序,这样您就不必这样做。但是现在,当任务变得漫长而混乱时,即使是最好的CUA也会跌跌撞撞。杂散的点击、延迟的回复或意外的弹出窗口可能会使整个跑步偏离正轨。小错误更是雪上加霜,而本应顺畅的自动化却变成了挫败感。
这就是核心瓶颈: 高方差。同一个特工可能会完成一次任务,然后在下次将其彻底摧毁。这种不一致使得 CUA 不可预测,也说明了为什么复杂的日常工作流程的可靠性仍然是一项挑战。
计算机用缩放剂
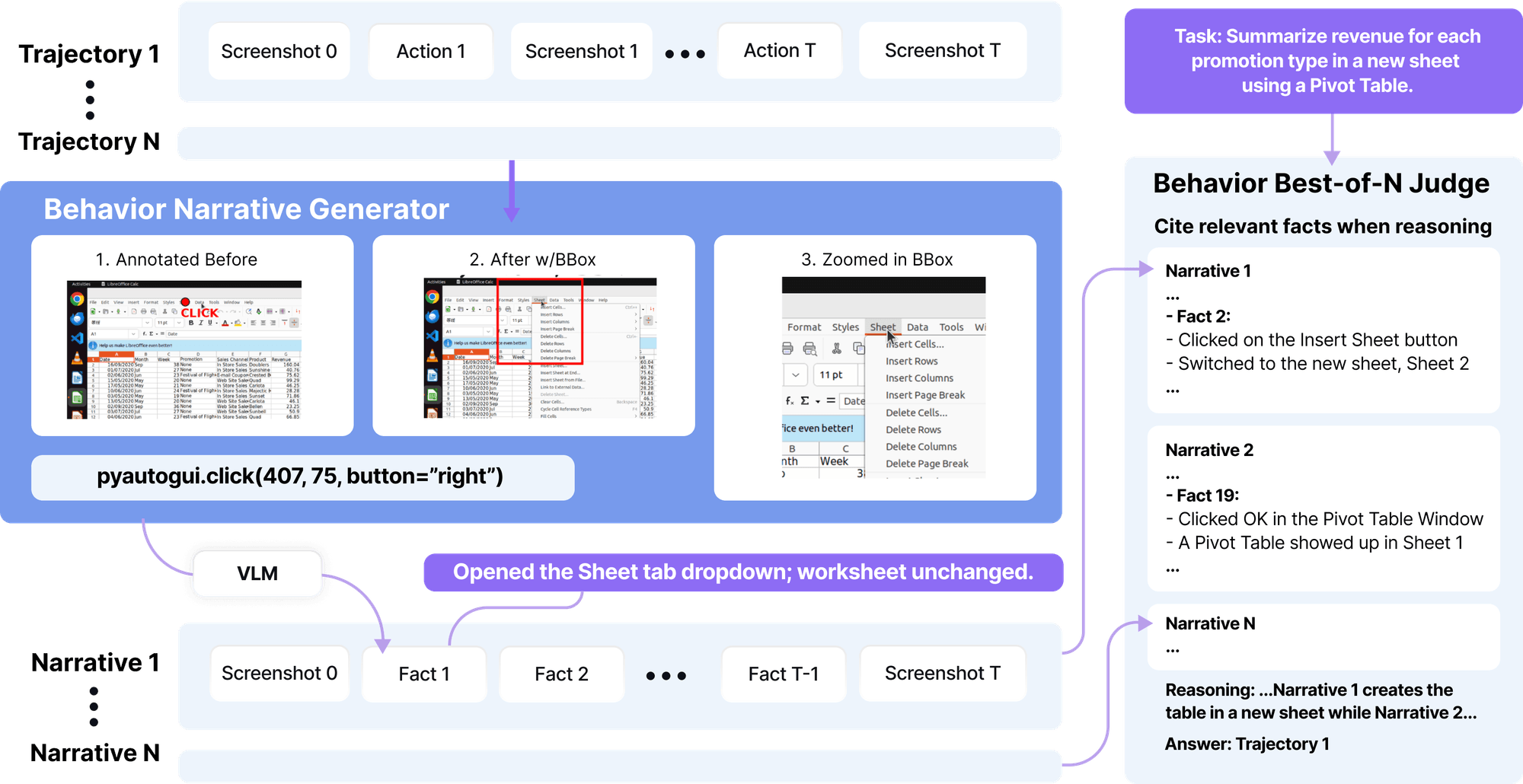
最佳行为:通过多次部署进行扩展
扩展代理面临的核心挑战是,即使使用更强的模型,单次发布仍然不一致。代理 S3 介绍 Behavior of-n (bbON),它通过并行运行多次部署并选择最佳部署来解决这个问题。
我们的方法从生成事实开始。原始代理运行包含大量的分步细节,其中许多是无关紧要或多余的。通过生成事实,我们将这些嘈杂的运行转化为关于每个步骤发生的事情的简明陈述,只关注与任务成功直接相关的信息。将这些事实串联起来会产生一种行为叙事,这清楚地总结了代理人在每个步骤中的所作所为,从而使代理的运行更易于解释,更易于比较。
在行为叙述到位后,我们会运用评委选择来确定哪种推广方案最能完成任务。法官没有比较原始产出,而是以每种行为叙述中的事实为依据做出裁决。通过在推出过程中引用这些事实,法官可以比较推理出哪种尝试最有效,并最终选择最佳方案。
改进框架:更简单的设计,更大的灵活性
Agent S2 使用了分层管理器—工作器设置,但这增加了不必要的开销。Agent S3 通过删除该层次结构并引入可以生成和执行代码的本机编码代理来简化框架。这使得解决方案更加多样化,涵盖了代码和 GUI 任务,也更加可靠。这些改进加起来将性能提高了约 13%,使代理 S3 的单代理性能达到了 62.6%。
通过代理运行进行扩展
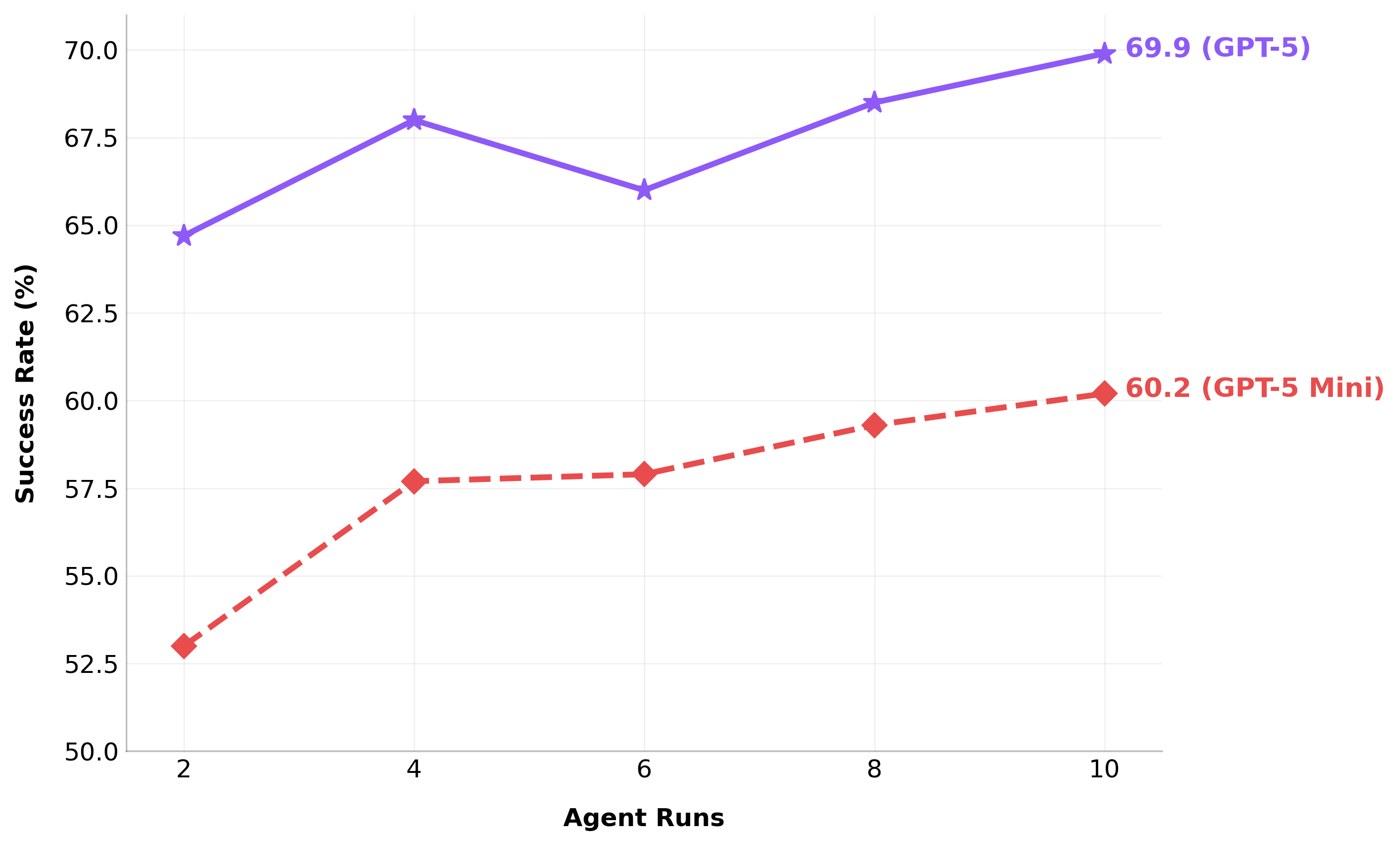
随着代理在 osWorld 上运行次数的增加,我们发现性能逐渐提高。在 10 次运行中,我们实现了最高性能,GPT-5 为 69.9%,GPT-5 Mini 为 60.2%。
人性化调整
我们研究了评委可以提高性能的任务(占OSWorld的44%),发现法官对78.4%的任务选择正确。当我们通过人工评估进行仔细检查时,我们发现判断实际上是正确的 92.8% 的任务,这使得 osWorld 的真实表现接近 76.3%。这表明我们的法官非常符合人类的偏好,使其成为评估CUA任务的有前途的工具。

What are the Key Features of a Computer Use Agent?
What functionalities does a computer use agent offer beyond basic automation?
A computer use agent goes beyond just automating tasks. It uses artificial intelligence to handle complex jobs and boost productivity. By integrating processes smoothly, users can automate workflows efficiently. AI capabilities help these agents analyze data, predict results, and adjust strategies, enhancing productivity.
How does modularity enhance the capabilities of a computer use agent?
Modularity improves a computer use agent by making it flexible and scalable. This setup allows for ongoing updates and customization to fit specific needs. Each module has its function, so users can upgrade parts without affecting the whole system. This adaptability helps agents keep up with changing technology, supporting growth and efficiency.
Can a computer use agent adapt to different operating systems and software applications?
Adaptability is vital for a computer use agent, ensuring it works well with varying operating systems and software. These agents integrate easily, maintaining performance on any platform, whether Windows, macOS, or Linux. Their broad compatibility means organizations can use them across diverse IT systems without facing issues.
How Does a Computer Use Agent Learn and Improve?
What learning mechanisms enable a computer use agent to adapt to user needs?
Computer use agents use machine learning and artificial intelligence to learn and adjust to user needs. They process large data sets to find patterns and make predictions. This helps them provide tailored solutions based on user behavior and preferences. By using feedback loops, they refine their operations for better accuracy over time. These systems effectively meet changing user demands with these methods.
How does a computer use agent handle unexpected situations or errors?
To manage unexpected situations or errors, computer use agents use strong error handling and automation. AI boosts their reliability by spotting and addressing anomalies quickly. These agents stay robust, preventing small issues from becoming serious problems. Automation in troubleshooting allows them to fix errors swiftly and keeps operations running smoothly even in unforeseen circumstances. This enhances user trust and system reliability.
What data privacy measures are implemented in a computer use agent?
Data privacy is crucial for computer use agents. They use strict security protocols to protect sensitive data and comply with regulations. Privacy measures include encrypting data during transmission and storage to guard against unauthorized access. Regular monitoring and updates of security systems help maintain data integrity. By focusing on data privacy, users can trust that their information is secure and handled properly.
What are the Practical Applications of Computer Use Agents?
Computer use agents, powered by artificial intelligence and automation, have a significant role in managing complex workflows. These advanced systems do more than just automate simple tasks. With their sophisticated reasoning abilities, they can handle intricate processes. Autonomous AI agents can organize multiple tasks, use resources efficiently, and keep workflows running smoothly. This technology is changing industries, helping businesses operate more efficiently and foster innovation with browser automation and AI workplace assistant.
Beyond automating simple tasks, what complex workflows can a computer use agent manage?
Computer use agents are deployed to handle complex workflows that need coordination and decision-making. These agents use artificial intelligence and automation to improve operations. Their advanced reasoning lets them assess situations, predict outcomes, and make decisions. This is useful in fields like logistics, finance, and healthcare that require quick adaptation to changing conditions.
How can a computer use agent improve productivity in specific professional contexts?
Using computer use agents in daily operations can greatly increase productivity and efficiency. In professional areas like project management or customer service, these agents automate regular tasks. This allows employees to focus on more strategic work. The innovative use of computer technology improves workflow and speeds up innovation, giving organizations a competitive edge.
What emerging technologies are integrated with advanced computer use agents?
The development of computer use agents is linked with advances in emerging technologies. Machine learning and foundation models, such as those from OpenAI, are crucial for these agents. These technologies allow agents to learn from data, adapt to new information, and improve over time. Continuous integration of new technology ensures that computer use agents remain highly effective across different domains.
Simular AI excels in this field by providing advanced solutions that use these technological developments. By keeping up with emerging technologies, Simular AI ensures its computer use agents are optimized for varied applications, offering great value to clients.
What are the Potential Limitations of Computer Use Agents?
What are the challenges in building truly reliable and trustworthy computer use agents?
Building reliable and trustworthy computer use agents involves several challenges. Integrating AI into these systems can create unexpected issues. This makes solid development protocols essential. It's important to ensure that automation aligns with human values and safety standards. To build trustworthy AI, we need to address biases, improve transparency, and perform thorough tests. Ongoing development and learning from real-world applications help enhance reliability.
How can the risk of errors and malfunctions be minimized in computer use agents?
Minimizing errors and malfunctions in computer use agents requires careful engineering practices and protocols. Advanced computing techniques should be used to detect and correct errors. Rigorous testing and simulation before deployment can help identify potential risks. Continuous monitoring after deployment allows for quick fixes. Effective risk management includes having fallback systems and regular software updates to fix vulnerabilities and boost operational stability.
What are the ethical considerations regarding the development and deployment of computer use agents?
When developing and deploying computer use agents, ethics are a major consideration. Protecting user data privacy and security is crucial. Developers must promote responsible AI use by setting transparent guidelines to prevent misuse or bias. Ethical considerations include assessing AI's impact on society and addressing job displacement concerns. Continuous dialogue among stakeholders is important for responsible development that aligns with societal values and legal standards.
How Can I Get Started with a Computer Use Agent?
What are the available options for accessing and utilizing computer use agent technology?
You have several options for accessing and using a computer use agent. Some popular software platforms include open-source solutions, which offer customization, and products from companies like Microsoft and Google. These platforms provide APIs, allowing seamless integration into your existing systems. Choosing the right one depends on your needs and how well it fits into your current technology setup.
What factors should be considered when choosing a computer use agent solution?
When picking a computer use agent, consider the following:
- Functionality: Make sure the agent fulfills your operational needs.
- Integration: Verify compatibility with your systems, such as OpenAI API.
- Cost: Look at both initial and ongoing costs.
- Support and Security: Check the availability of support and the strength of security features.
- User Interface: Ensure it's easy to use and intuitive for users.
By assessing these points, you can find a solution that meets your organization's goals and technical needs.
Where can I find resources and support for learning more about and using computer use agents?
To learn more about using computer use agents, consider these resources:
- Tutorials and Documentation: You can find guides on GitHub and the official websites of platforms like Microsoft Azure and OpenAI.
- Community Forums: Join forums to gain insights and practical knowledge from other users.
- Training Programs: Participate in training sessions by providers or external educators for hands-on experience.
- Learning Resources: Many online platforms offer courses and materials focusing on different aspects of computer use agents.
These resources will help you fully utilize your chosen computer use agent technology.
What are the benefits of using an autonomous agent for computer use?
Autonomous agents can automate and optimize computer use, improving efficiency. They help manage complex tasks, reduce human errors, and increase productivity by adapting to specific user needs.
How can a computer agent improve cyberattack management?
A computer agent analyzes suspicious behavior in real time to reinforce security against cyberattacks. It monitors networks, detects anomalies, and initiates quick responses to minimize risks.
What is the role of artificial intelligence in computer foundation models?
Artificial intelligence enhances foundation models by improving natural language understanding, which facilitates processing and analyzing complex data. It supports the development of innovative and user-friendly solutions.
Why is it important to consider user interfaces when implementing computer agents?
User interfaces ensure smooth interaction between computer agents and users. They make functionalities accessible and understandable, thereby improving user experience and operational efficiency.
How do navigation agents affect computer software usage?
Navigation agents simplify software interaction by guiding users through complex processes. They facilitate task customization and automation, optimizing software use.
What role do usage agents play in improving organizational workflows?
Usage agents automate redundant tasks and integrate various tools to create efficient workflows. They enable smooth operation management, reduce response times, and boost productivity in organizations.
How can computer agent usage strategies adapt to current work environments?
Computer agent strategies adapt by integrating emerging technologies like federated learning and multimodal models. These approaches make systems more flexible and responsive to changing work environment dynamics.
What are advanced language models, and how do they influence interaction with computer agents?
Advanced language models, such as large language models, enhance computer agents' ability to understand and generate human text. This leads to more natural and effective interactions, enriching the overall user experience.
Key Insights
- We offer advanced solutions for computer use agents in regions such as California, Canada, Florida, New York, Texas, the United Kingdom, and Washington.
- Our platform utilizes state-of-the-art computer use software to enhance computer utilization, positioning it as a leading intelligent system.
- Experience seamless interaction with user agents in GUI and UI design, which provides innovative navigation and autonomous agents.
- Work alongside industry leaders like Bill Gates and Sam Altman on groundbreaking projects in AI technology and sandbox environments.
- Engage with foundation models and large language models (LLMs) for top performance, backed by notable researchers like Ilya Sutskever.
- Gain insights into AI with resources from IEEE, MIT Technology Review, and publications on trustworthy AI practices.
- Prioritize secure computing environments to shield against cyber attacks, using tools and protocols for strong data integrity.
- Innovate with AI-driven solutions through platforms like OpenAI's ChatGPT and DALL-E, supported by pioneers such as Kai-Fu Lee.
- Access our suite of tools, including apps, plugins, and AI technologies that transform user interaction.
- Improve efficiency with AIOps for incident management and federated learning, optimizing organizational strategies and workflows.
- Enhance emotional well-being and decision-making through effective AI applications in business scenarios.
- Use advanced reasoning and adaptive systems for solving complex problems and strategic initiatives.
- Stay updated with the latest developments in AI, focusing on practical applications and emerging technologies.
- Apply machine learning across sectors, ensuring compliance and ethical standards in deployment.
- Explore uses of GPT and AGI in real-world situations through demonstrations, evaluations, and scholarly citations.
- Navigate the AI landscape with expertise, using resources like stargate datasets, deepfake prevention, and open-source contributions.
- Integrate AI seamlessly into existing agentic frameworks with reference implementations and best practice guidelines.
- Encourage AI innovation in computing, fostering community engagement and collaborative growth in tech.
- Enhance potential with AI-powered solutions for data analysis, automation, and process optimization across industries.
- Connect with professionals on platforms like LinkedIn to explore trends, job opportunities, and advancements in AI.
- Optimize your digital experience with tools designed for efficient browsing, communication, and information management.
- Maintain robust cybersecurity measures and safe data practices in all AI deployments and integrations.
准备好使用你的
用类似的方式计算机?
共享和整理您的记忆,并对任务进行个性化设置。