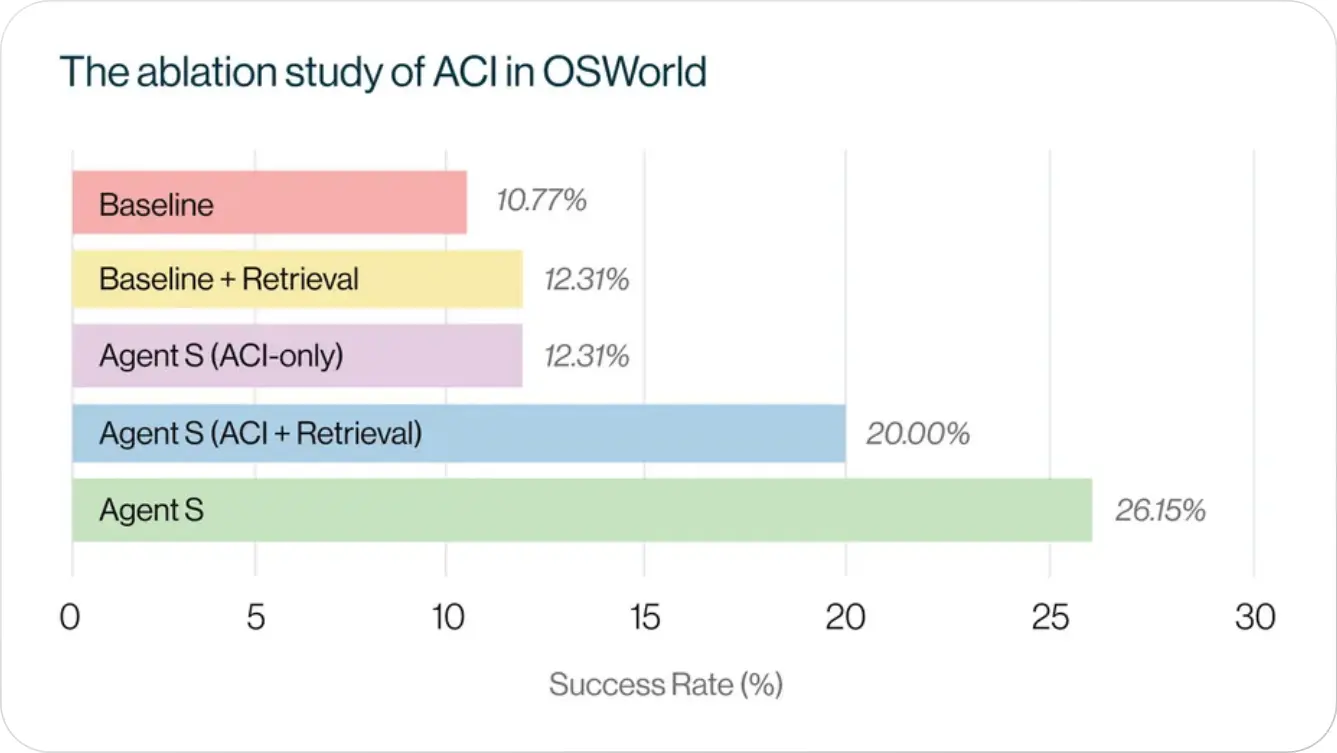
Understanding the AI Agentic Framework
The AI agentic framework is a modern approach that combines artificial intelligence (AI) with agent-based modeling. This combination aims to improve decision-making processes. With this framework, intelligent agents can work on their own within a system, which makes workflows smoother and promotes collaboration. By using machine learning and automation, the agentic framework creates a solid foundation for developing multi-agent systems that adjust to various situations.
Here are some key components of this framework:
- Intelligent Agents: These software entities can take independent actions to achieve specific goals.
- Decision-Making Algorithms: These algorithms help agents make informed choices based on the information they receive.
- Agent Systems: This refers to groups of interconnected agents collaborating to complete complex tasks.
Microsoft and other tech leaders are using this framework to create smarter applications that need less human involvement.
Key Concepts of the Agentic Framework
The agentic framework includes several important concepts that are essential for its successful application:
- Agent-Based Framework: A setup where individual agents work together to accomplish tasks, boosting efficiency.
- Agentic Approach: This method encourages agents to act independently and highlights their ability to learn and adapt.
- Workflows: Built in AI workplace assistants, these are the planned paths that agents follow to enhance processes and ensure smooth task execution.
- Human-Agent Interaction: This is how humans communicate and guide the agents.
By incorporating languages like Python, developers can effectively use design patterns, adaptive agents, and debugging methods. This integration helps create better feedback loops and improves the overall performance of the system.
Applications of AI Agentic Framework
The applications of the AI agentic framework are broad and relevant across various fields:
- AI Framework Variations: Different types can be adjusted to meet specific industry needs, ensuring flexibility.
- AI Solutions: From virtual assistants to intricate management systems, these solutions expand operational possibilities.
- Agent Orchestration: This involves coordinating multiple agents to achieve unified results.
- Security and Management: The framework helps boost organizational efficiency while upholding security standards.
Prominent examples include platforms like GitHub and tools such as Langchain, showcasing how agentic AI can be implemented in real-world settings. These applications illustrate how intelligent systems can reshape business functions and enhance user experiences.
Benefits of Using an Agentic Framework
Using an agentic framework comes with many advantages:
- Efficiency: It increases productivity by automating repetitive tasks, reducing the need for manual work.
- Quality Management: The framework ensures consistent quality in results through structured processes.
- Continuous Integration: Updates and improvements become easier, keeping the systems current and effective.
- Cooperative Agents: It encourages collaboration among different agents, leading to improved problem-solving abilities.
This framework also addresses ethical concerns in AI, promoting transparency and responsible use of self-learning agents.
Challenges in Implementing Agentic Frameworks
While there are clear benefits, organizations may face a few challenges when adopting agentic frameworks:
- Data Privacy: Protecting sensitive data is critical when implementing intelligent systems.
- AI Governance: Setting regulations is necessary to manage the proper use and oversight of AI technologies.
- Agent Performance Metrics: Finding suitable metrics to measure how well agents perform their tasks is essential.
- Real-Time Agents: Managing agents in fast-paced environments requires advanced strategies and resilient systems.
Tackling these challenges is vital for successfully integrating the AI agentic model into existing systems to ensure safety and trustworthiness.
Conclusion
The AI agentic framework shows promise in the realm of artificial intelligence by providing a structured way to effectively utilize intelligent systems. By grasping its core concepts, applications, benefits, and challenges, organizations can better leverage AI to foster innovation and enhance efficiency.
Feel free to explore more about the AI agentic framework or share your opinions in the comments! Your questions and insights are valuable as we move forward in this exciting field.
Understanding the AI Agentic Framework
The AI agentic framework is a collection of ideas and methods aimed at creating intelligent systems that can act and make decisions on their own. This framework enhances collaboration between human users and artificial intelligence (AI) agents, promoting smooth workflows and effective automation.
Key aspects of the agent-based framework include:
- Intelligent Agent Frameworks: These form the foundation for developing AI solutions that function in real-time.
- Collaboration Mechanisms: Good communication among multiple agents boosts system performance.
- Human-Agent Interaction: This part emphasizes how people can work alongside cognitive agents, leading to better experiences.
- Multi-Agent Systems: Different agents work together to accomplish complex tasks, which may be too much for a single agent to handle.
You can see real-world applications of this framework in areas like healthcare, finance, and logistics, where AI applications enhance processes, lower mistakes, and improve results.
Key Components of an Agentic Approach
An agentic approach consists of essential components that define how it works and its effectiveness.
- Agent Autonomy: The level of independence an agent has is crucial for effective automation.
- Decision-Making Algorithms: These allow agents to evaluate situations and make smart choices based on current data.
- Agent-Based Modeling: This method helps simulate interactions within a system, improving understanding and optimization.
- Design Patterns: Established design patterns assist with programming agent systems, making them easier to maintain and scale.
- Agent Cooperation: Successful implementation depends on agents working together smoothly.
A strong agentic model includes these components, enabling powerful agent technologies that drive innovation across various sectors.
Applications of the AI Agentic Framework
The AI agent framework has many applications across different sectors, highlighting its flexibility and effectiveness.
Some noteworthy examples are:
- Project Management: AI agents improve project workflows, ensuring tasks are completed quickly and on time.
- Data Privacy: Intelligent agents help manage sensitive data while ensuring compliance with regulations like GDPR.
- Autonomous Agents: These self-operating agents take care of repetitive tasks, such as entering data so that humans can concentrate on strategic work.
- Task-Oriented Agents: Designed to perform specific functions, these agents carry out tasks with great accuracy.
Leading companies like Microsoft and Nvidia utilize the agentic AI framework, showing how AI capabilities can be integrated effectively into their operations.
Benefits of Implementing Agentic Systems
Implementing agentic systems brings a variety of benefits that can boost efficiency and effectiveness in organizations:
- Automation: Cuts down on manual work, speeding up task completion.
- Ease of Use: Built with user experience in mind, making acceptance simple.
- Real-Time Analytics: Offers instant feedback, supporting data-driven decisions.
- AI Ethics: Complies with ethical standards, building trust with users.
- Performance Metrics: Measures agent effectiveness, promoting continuous improvement.
These benefits explain why many organizations are adopting agentic variations to stay competitive in their fields.
Challenges and Considerations
While the agentic framework offers many chances for improvement, it also presents challenges that businesses should think about:
- Security Risks: Protecting data and systems from cyber threats is crucial.
- Complexity: Creating and implementing multi-agent systems can be intricate and time-consuming.
- Data Governance: Organizations must follow regulations and best practices for data management.
- AI Accountability: Figuring out who is responsible when AI makes decisions is an important concern.
Addressing these challenges requires a solid grasp of the framework's varieties and the underlying technologies, along with effective governance and accountability strategies in distributed AI systems.
Call to Action
Are you interested in exploring the potential of the AI agentic framework? Join the conversation below, share your thoughts, or learn more about how Simular AI can assist you in embracing intelligent automation.
Understanding the AI Agentic Framework
The AI Agentic Framework marks a significant change in how we design and use artificial intelligence (AI) systems. This framework aims to create intelligent systems that can make decisions on their own, work together with other agents, and adjust to changing environments. It serves as a foundational structure for cognitive agents to interact, manage workflows, and respond to dynamic situations effectively.
Key aspects include:
- Agent-based Approach: This involves using independent entities that act according to specific guidelines and goals.
- Multi-Agent Systems: These systems enable various agents to collaborate, which boosts overall efficiency and effectiveness.
- Decision-Making Algorithms: These sophisticated algorithms help agents make informed choices by analyzing available data and context.
By leveraging this framework, AI can perform tasks more like humans do, leading to increased productivity and innovative applications across various fields.
Key Components of Agentic AI Systems
To build successful agentic AI systems, several key components need to be considered:
- Management Tools: These tools help streamline coordination among agents to ensure smooth operation.
- Automation Features: Automation minimizes the need for manual input, which enhances process efficiency.
- Reasoning Capabilities: Intelligent agents utilize strong reasoning skills to evaluate situations and make sound decisions.
- Design Patterns: By implementing established design patterns, developers can effectively structure complex agent systems.
- Debugging Tools: These tools are vital for maintaining system reliability by quickly identifying and fixing issues.
- Agent Collaboration Mechanisms: Encouraging cooperation among agents is essential for achieving complex objectives.
Together, these components work to enhance the effectiveness of the agentic approach, paving the way for advanced AI solutions.
Applications of the Agentic Framework in AI
The agentic framework supports a wide range of applications that can greatly benefit different industries:
- Virtual Agents: Often used in customer support, these agents provide 24/7 assistance, improving user satisfaction.
- Autonomous Agents: In logistics and supply chain management, these agents optimize delivery processes.
- Human-Agent Interaction: The framework helps improve user interfaces for better engagement and accessibility when used to build AI agent apps like ai browser automation.
- Data Integration: It enables seamless connectivity between various data sources which enriches decision-making.
- Feedback Mechanisms: These allow agents to learn from interactions, enhancing their capabilities over time.
This broad versatility illustrates how the framework adapts to different sectors, from finance to healthcare.
Challenges and Considerations
While the AI agent framework holds great potential, it also brings along certain challenges:
- Data Privacy Concerns: With the increase in data usage, protecting personal information becomes essential.
- Security Risks: Addressing vulnerabilities is crucial to safeguarding against cyber threats.
- Ethical Considerations: The deployment of AI must follow ethical standards to prevent misuse.
- Project Management Complexity: Coordinating multiple agent systems requires effective leadership and clear guidelines.
- Performance Metrics: Setting performance metrics for agents is important for measuring success and adjusting strategies.
Tackling these challenges is important for the successful rollout of agentic systems, ensuring they remain efficient, secure, and ethically sound.
Overall, the AI Agentic Framework lays a solid foundation for developing advanced AI systems. By focusing on collaborative, intelligent agents, organizations can reach new heights in efficiency and creativity. As you explore the potential applications of this framework, keep in mind its benefits and the challenges that may arise to maintain a balanced approach to AI deployment.
If you found this information useful or have questions, feel free to share your thoughts below or distribute this article to others interested in the evolving landscape of AI.



.webp)
.webp)