So automatisieren Sie die Codeüberprüfung mit Claude Code
Erfahren Sie, wie Sie die Codeüberprüfung mit Claude Code automatisieren können. In diesem Handbuch geht es um die Einrichtung von PR-Reviews, die Subagent-Architektur und darum, wie man visuelle QA hinzufügt, die erfasst, was bei einer diffbasierten Überprüfung übersehen wird.
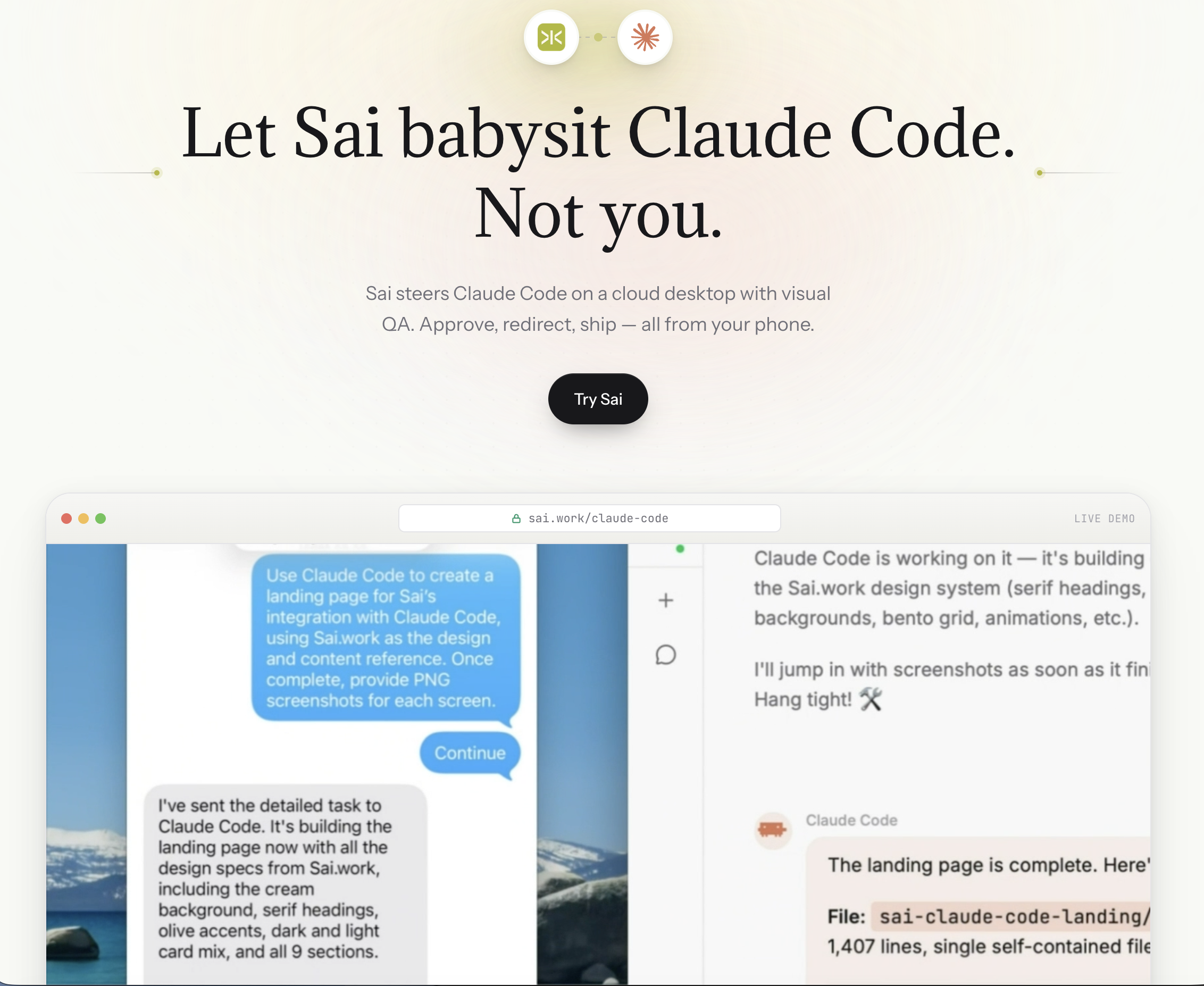
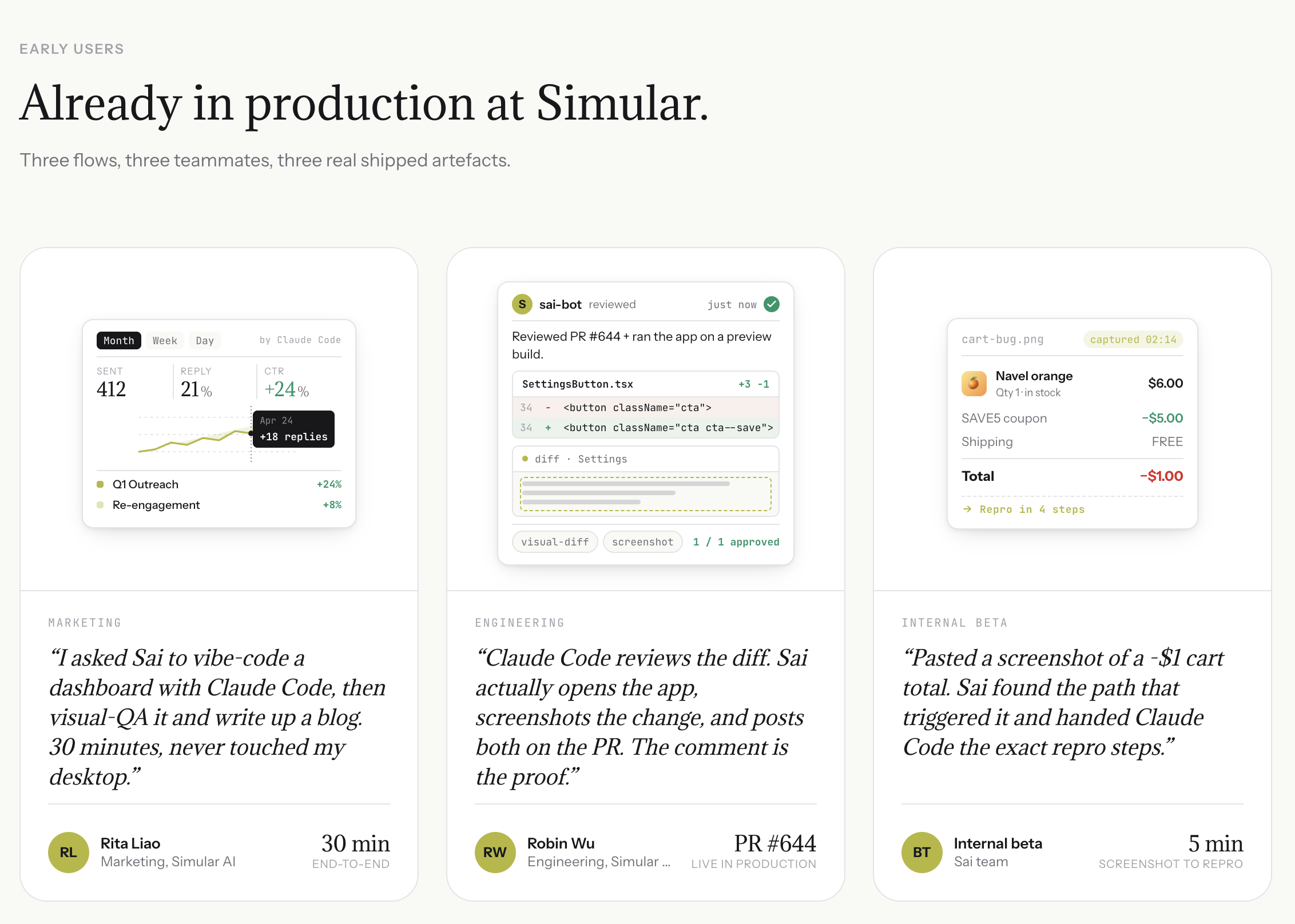
Wenn eine PR geöffnet wird, liest Sai nicht nur den Unterschied — es öffnet deine Vorschau-Bereitstellung, loggt sich in ein Testkonto ein und klickt sich Schritt für Schritt durch die betroffenen Nutzerabläufe. Es macht Screenshots von jedem Zustandsübergang und kennzeichnet alles, was nicht funktioniert. So erhalten die Prüfer visuelle Beweise statt Codekommentare.
Automatisierte Fehlerreproduktion anhand von Screenshots
Fügen Sie den Bug-Screenshot eines Benutzers in Sai ein. Es untersucht die App, ermittelt die genaue Reihenfolge der Klicks, die das Problem ausgelöst haben, und generiert ein für die Entwicklung geeignetes Ticket mit Schritten zur Reproduktion, erwartetem Verhalten und kommentierten Screenshots. So werden vage Berichte in einen umsetzbaren Kontext für Claude Code umgewandelt.
Fix-Verifizierung im geschlossenen Regelkreis
Nachdem Claude Code den Code gepatcht hat, führt Sai denselben Testablauf automatisch erneut aus. Es erfasst Vorher-Nachher-Screenshots, überprüft Sentry auf neue Fehler und veröffentlicht einen strukturierten Bericht über bestanden/nicht bestanden auf Slack oder GitHub. So führt dein Team nie einen Fix zusammen, ohne zu bestätigen, dass er tatsächlich im Produkt funktioniert.
Der Code-Review-Engpass, über den niemand spricht
Ihr Team versendet schneller als es überprüft.
KI-Codierungsagenten — Claude Code, Cursor, GitHub Copilot — generieren Pull-Requests schneller, als ein menschlicher Reviewer sie lesen kann. Ein leitender Ingenieur, der früher vor dem Mittagessen drei PRs überprüft hat, sieht sich jetzt zwölf gegenüber. Der Code sieht sauber aus. Die Tests bestehen. Der Linter ist leise.
Aber die Checkout-Seite ist kaputt.
Dies ist die Lücke bei der Codeüberprüfung im Jahr 2025: der Abstand zwischen „Der Code ist korrekt“ und „Das Produkt funktioniert“. Herkömmliche Code-Reviews — ob durch Menschen oder KI — ergeben Unterschiede. Es überprüft Logik, Muster und Syntax. Es öffnet nicht die App, klickt nicht durch den Checkout-Prozess, wendet einen Coupon an und stellt fest, dass der Gesamtbetrag auf minus vier Dollar sinkt.
Die meisten KI-Code-Review-Tools vergrößern diese Lücke, nicht kleiner. Sie generieren mehr Kommentare, mehr Vorschläge, mehr Lärm. Techniker auf Reddit beschreiben das Muster so: „Die Überprüfung durch KI verursacht mehr Arbeit als sie spart, weil für jeden Kommentar ein Mensch benötigt wird, um zu überprüfen, ob er echt ist.“
Das Problem ist nicht, dass die Codeüberprüfung zu langsam ist. Das Problem ist, dass die Codeüberprüfung unvollständig ist. Es überprüft den Code. Niemand bewertet das Produkt.
In diesem Handbuch werden drei Stufen der Automatisierung der Codeüberprüfung beschrieben:
Manuelle Überprüfung — wie die meisten Teams das heute machen
Bewertung von Claude Code — automatisierte Diff-Analyse mit /rezension und GitHub-Aktionen
Verhaltensorientierte Überprüfung — Claude Code liest den Code, während Sai das Produkt testet
Am Ende werden Sie genau wissen, wie Sie die einzelnen Stufen einrichten, wann Sie welche verwenden müssen und woher die tatsächlichen Zeiteinsparungen kommen.
Wie Claude Code Pull-Requests überprüft
Claude Code ist der KI-Codierungsagent von Anthropic, der in Ihrem Terminal läuft. Es liest Ihre Codebasis, versteht den Projektkontext und kann Code auf einer Ebene überprüfen, die weit über einfaches Linting hinausgeht.
Der Befehl /review
Der schnellste Weg, um eine Claude Code-Bewertung zu erhalten, ist der integrierte /rezension Befehl:
# Review your current working changesclaude review
# Review a specific PRclaude review --pr 142
Claude Code analysiert den Unterschied mithilfe mehrerer spezialisierter Subagenten:
Logikprüfer — Prüfungen auf Richtigkeit, Randfälle und Regressionen
Sicherheitsprüfer — Scans nach Sicherheitslücken, geheimen Enthüllungen und Injektionsvektoren
Stilprüfer — setzt Namenskonventionen, Muster und Lesbarkeitsstandards durch
Architekturgutachter — weist auf strukturelle Probleme und Musterverstöße hin
Jeder Subagent konzentriert sich auf seine Domäne und berichtet unabhängig. Das Ergebnis ist eine strukturierte Überprüfung mit kategorisierten Ergebnissen, Schweregraden und Lösungsvorschlägen.
Claude Code als GitHub-Aktion
Für die automatische PR-Überprüfung bei jedem Push bietet Claude Code eine GitHub-Aktion an:
Liest den vollständigen Diff plus den umgebenden Kontext
Veröffentlichen Sie Inline-Kommentare zu bestimmten Zeilen
Fügt einen zusammenfassenden Kommentar mit Gesamtbewertung hinzu
Sie können Bewertungen auch manuell auslösen, indem Sie einen Kommentar abgeben @claude Bewertung auf jeder PR.
Was Claude Code Review gut macht
Die Bewertung von Claude Code ist wirklich nützlich für:
Logikfehler erkennen das erfordert das Verständnis des Codebasiskontextes, nicht nur der geänderten Zeilen
Identifizierung fehlender Fehlerbehandlung — es liest den umgebenden Code und bemerkt, wenn eine Funktion, die werfen kann, ohne Try/Catch aufgerufen wird
Regressionen erkennen — es versteht, was der Code zuvor gemacht hat, und meldet, wenn neue Änderungen das bestehende Verhalten beeinträchtigen
Verringerung der Übermüdung der Prü — es kümmert sich um die mechanischen Prüfungen, sodass sich menschliche Prüfer auf Architektur- und Produktentscheidungen konzentrieren können
Was Claude Code Review nicht kann
Claude Code überprüft den Code. Es führt keinen Code aus. Das bedeutet, dass es nicht:
Öffnen Sie einen Browser und testen Sie die eigentliche Benutzeroberfläche
Stellen Sie sicher, dass eine CSS-Änderung auf verschiedenen Bildschirmgrößen korrekt aussieht
Prüfen Sie, ob ein Zahlungsfluss von Anfang bis Ende abgeschlossen ist
Beachten Sie, dass eine Schaltfläche jetzt hinter einem anderen Element versteckt ist
Reproduzieren Sie einen Fehler aus einem Benutzer-Screenshot
Greifen Sie auf Tools mit Autorenwänden wie Sentry, Datadog oder Admin-Dashboards zu
Dies ist keine spezielle Einschränkung von Claude Code — es ist die grundlegende Einschränkung der differenzbasierten Überprüfung. Kein Tool, das nur Code liest, kann Ihnen sagen, ob das Produkt funktioniert.
The Gap: Was AI Code Review immer noch vermisst
Hier ist ein reales Szenario. Ihr Team verwendet Claude Code Review bei jeder PR. Es ist konfiguriert, läuft und fängt echte Bugs ab. Dann passiert das:
PR #247: Gutscheinlogik für Warenkorrabatte aktualisieren
Claude Code überprüft den Unterschied und findet:
Keine Logikfehler bei der Rabattberechnung
Korrekte Nullprüfungen für das Coupon-Objekt
Die Tests bestehen, um den Gutschein anzuwenden/zu entfernen
Keine Sicherheitsprobleme
Die PR wird zusammengeführt.
Zwei Stunden später berichtet ein Nutzer: „Ich habe einen Gutschein im Wert von 5$ auf meinen Warenkorb angewendet und dann einen Artikel entfernt. Der Gesamtbetrag ist jetzt negativ. Ich kann nicht auschecken.“
Was ist passiert? Die Coupon-Logik war für sich genommen richtig. Doch die Interaktion zwischen Coupon-Anwendung und Entfernung des Warenkorb-Artikels führte zu einem Zustand, den kein Test abdeckte und kein anderer Prüfer — ob Mensch oder KI — allein durch das Lesen des Codes auffangen konnte.
Dies ist die Klasse von Bugs, die wächst, wenn Codebasen komplexer werden:
Fehler bei der staatlichen Interaktion — zwei Funktionen, die unabhängig voneinander funktionieren, aber zusammenbrechen
Flussabhängige Fehler — Probleme, die erst nach einer bestimmten Abfolge von Benutzeraktionen auftreten
Umgebungsspezifische Fehler — Inszenierung verhält sich anders als lokal
Diese Bugs haben ein gemeinsames Merkmal: Sie können sie nur finden, indem Sie das Produkt verwenden.
The Full Loop: So führt Sai + Claude Code Code-Reviews durch
Sai ist ein KI-Agent das läuft auf einem Cloud-Desktop. Es kann Browser öffnen, sich durch Anwendungen klicken, Screenshots machen, Fehlerprotokolle lesen und mit Tools wie Sentry, Slack und GitHub interagieren — und das alles, während es autonom läuft.
Traditionelle KI-Überprüfung: PR öffnet → KI liest Diff → KI veröffentlicht Kommentare → Mensch verifiziert
Bewertung von Sai + Claude Code:PR öffnet → Claude Code liest Diff → Sai öffnet die App → Sai testet die Flows → Probleme mit den Screenshots von Sai → Claude Code korrigiert den Code → Sai testet erneut → Strukturierter Bericht veröffentlicht
Der entscheidende Unterschied: Claude Code überprüft den Code. Sai rezensiert das Produkt.
So funktioniert der 8-Stufen-Loop
Schritt 1: Trigger
Die Schleife beginnt an einer von drei Quellen:
Ein GitHub-PR wird geöffnet oder aktualisiert (Webhook-Trigger)
Ein Nutzer meldet einen Bug („Die Summe der Kaufabwicklung ist negativ, nachdem ein Coupon eingelöst wurde“)
Ein Sentry-Alarm wird mit einem neuen Fehler ausgelöst
Traditionelle Bewertungen beginnen mit dem Unterschied. Diese Schleife kann von der Benutzererfahrung ausgehen.
Schritt 2: Claude Code analysiert den Code
Claude Code liest den PR-Diff, versteht den Codebasiskontext und identifiziert potenzielle Probleme auf Codeebene — Logikfehler, fehlende Randfälle, Sicherheitsbedenken.
Schritt 3: Sai öffnet die Vorschau-Bereitstellung
Während Claude Code den Code liest, öffnet Sai die Vorschau-URL in einem echten Browser auf seinem Cloud-Desktop. Es meldet sich mit einem Testkonto an und navigiert zum betroffenen Bereich.
Schritt 4: Sai testet die tatsächlichen Benutzerströme
Dies ist der entscheidende Schritt, den kein anderes KI-Review-Tool durchführt. Ich sagte:
Fügt Artikel zum Einkaufswagen hinzu
Wendet den Gutscheincode an
Ändert Mengen und entfernt Artikel
Erlös zur Kasse
Überprüft, ob Gesamtbeträge, Steuern und Rabatte korrekt berechnet werden
Screenshots bei jedem Schritt
Schritt 5: Sai generiert Schritte zur Reproduktion
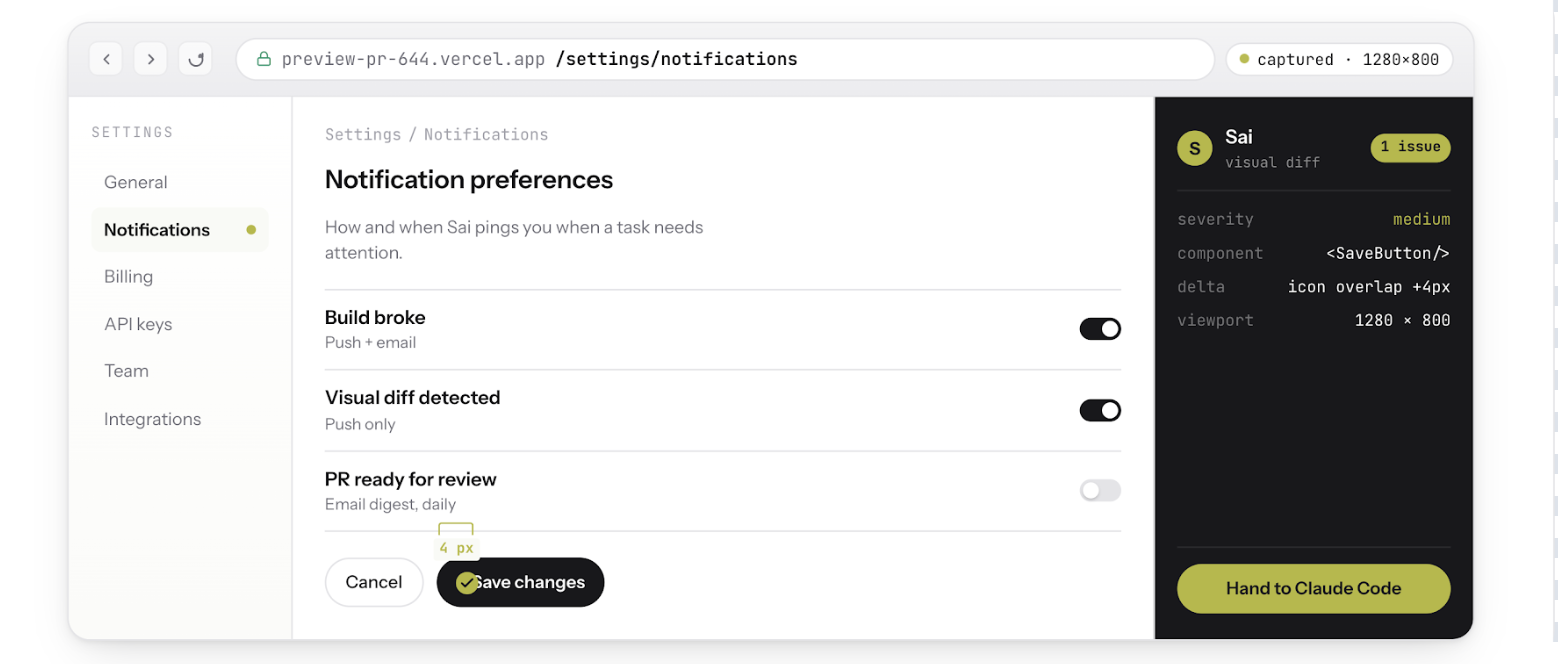
Schritte zur Reproduktion:1. Füge 3 Orangen zu je 2$ hinzu. Gesamtbetrag des Einkaufswagens: 6,002$. Wenden Sie den Gutscheincode SAVE5 an. Gesamtbetrag des Warenkorbs: 1.003$. Entferne eine Orange. Gesamtbetrag des Warenkorbs: -1.004 $. Klicken Sie auf Zur Kasse. Fehler: „Negative Summe kann nicht verarbeitet werden“ Erwartet: Der Gesamtbetrag sollte als 4,00$ neu berechnet werden — 4,00$ (begrenzt) = 0,00$ Aktuell: Insgesamt wird angezeigt -1,00 $ Screenshots: [before_coupon.png] [after_remove.png] Konsolenfehler: NoneSentry: Keine neuen Fehler protokolliert
Dies ist kein vager Kommentar zu einem Unterschied. Das ist ein QA-Ticket mit Beweisen.
Schritt 6: Claude Code korrigiert den Code
Claude Code erhält die strukturierten Reproduktionsschritte, Screenshots und den Fehlerkontext von Sai. Anstatt zu erraten, was falsch sein könnte, weiß es genau:
Welche Seite ist betroffen
Welche Operationssequenz löst den Bug aus?
Was sollte das erwartete Verhalten sein
Was ist das tatsächliche Verhalten
Es generiert eine gezielte Lösung — keinen spekulativen Vorschlag.
Schritt 7: Sai testet den Fix erneut
Nachdem Claude Code den Code gepatcht hat, führt Sai dieselbe Testsequenz erneut aus:
Stellen Sie sicher, dass die Summe nicht mehr negativ wird
Vorher/Nachher-Screenshots aufnehmen
Sentry auf neue Fehler überprüfen
Schritt 8: Strukturierter Bericht an Slack/GitHub
Das Endergebnis ist ein strukturierter QA-Bericht, der auf dem Kanal deines Teams veröffentlicht wird:
Sai QA Review: PR #247 — Coupon Discount Logic
Status: ✅ Fixed and verified
Issue found:
Cart total became negative when removing items after applying coupon.
Root cause:
Coupon discount was applied as fixed amount without
recalculating against updated cart total.
Fix applied:
Added cap logic — discount cannot exceed current cart subtotal.
Verification:
- Before fix: Total = -$1.00 after removing item [screenshot]
- After fix: Total = $0.00, coupon capped correctly [screenshot]
- Sentry: No new errors
- Checkout flow: Completes successfully
Schritt für Schritt: Claude Code Review mit Sai einrichten
Voraussetzungen
Ein GitHub-Repository mit Vorschaubereitstellungen (Vercel, Netlify oder ähnlich)
Ein Claude Code-Konto (zur Codeanalyse)
Ein Sai-Account (für visuelle Qualitätssicherung und Browsertests)
Schritt 1: Claude Code GitHub Action einrichten
Füge die Claude Code-Review-Aktion zu deinem Repository hinzu:
Auf diese Weise erhalten Sie eine automatische Überprüfung jeder PR auf Diff-Level.
Schritt 2: Verbinde Sai mit deinem GitHub-Repository
Richten Sie in Sai einen Webhook-Workflow ein, der bei PR-Ereignissen ausgelöst wird:
Öffnen Sie Sai → Einstellungen → Workflows
Erstellen Sie einen neuen Webhook-Workflow
Wähle GitHub als Anbieter
Wähle dein Repositorium
Setze das Triggerereignis auf pull_request.geöffnet
Schritt 3: Testabläufe definieren
Sag Sai, was er testen soll, wenn eine PR bestimmte Bereiche berührt:
When a PR modifies files in /src/checkout/:
1. Open preview deployment URL
2. Log inwith test account
3. Add 3 items to cart
4. Apply coupon TESTCOUPON
5. Modify quantities
6. Remove one item
7. Proceed to checkout
8. Screenshot each step
9. Report any total that is negative or mismatched
Schritt 4: Reporting konfigurieren
Wählen Sie aus, wohin Sai die Ergebnisse sendet:
GitHub PR-Kommentar — im Einklang mit dem Code-Review
Slack-Kanal — für Teamsichtbarkeit
Lineares Ticket — für Blocker, die Tracking benötigen
Schritt 5: Ausführen und iterieren
Die ersten PRs kalibrieren das System. Sai lernt, in welchen Strömen Materie fließt, wie „richtig“ aussieht und wo falsch positive Ergebnisse auftreten. Nach einer Woche verfügen Sie über eine Überprüfungspipeline, die sowohl Probleme auf Codeebene als auch auf Produktebene automatisch erkennt.
Aspect
Tier 1: Manual
Tier 2: Claude Code
Tier 3: Claude Code + Sai
Setup time
None
15 min (GitHub Action)
30 min (webhook + flows)
Review speed
30-60 min / PR
2-5 min / PR
3-7 min / PR
Catches logic bugs
✅
✅
✅
Catches visual bugs
❌
❌
✅
Tests user flows
❌
❌
✅
Provides evidence
Text comments
Inline comments
Screenshots + STR
Verifies fixes
Manual re-review
❌
✅ Automated re-test
Human time / PR
30-60 min
10-15 min
2-5 min
Fünf reale Szenarien
Szenario 1: E-Commerce-Checkout-Bug
Auslöser: PR aktualisiert die Logik der Zahlungsabwicklung.
Claude Code findet: Fehlende Fehlerbehandlung für abgelehnte Karten.
Sai findet: Nach einer abgelehnten Karte bleibt die Schaltfläche „Bestellung aufgeben“ deaktiviert, auch wenn der Benutzer eine gültige Karte eingibt. Der Ladespinner wird nie gelöscht.
Ergebnis: Claude Code behebt die Fehlerbehandlung. Sai überprüft, ob die Schaltfläche nach einer erfolgreichen Karteneingabe wieder aktiviert wird. Ein auf Slack veröffentlichter Bericht.
Szenario 2: Unterbrechung des responsiven Designs im Dashboard
Auslöser: PR überarbeitet das Dashboard-Rasterlayout.
Claude Code findet: Keine Logikprobleme. CSS-Änderungen sehen korrekt aus.
Sai findet: Im Tablet-Viewport (768 Pixel) überlappt die Seitenleiste den Hauptinhaltsbereich. Zwei Diagramm-Widgets sind vollständig hinter dem Navigationsbereich versteckt.
Ergebnis: Sai zeigt die Überlappung an drei Haltepunkten. Claude Code passt die Raster-Breakpoint-Werte an. Sai testet erneut und bestätigt, dass das Layout bei allen Größen sauber ist.
Szenario 3: Regression des Authentifizierungsflusses
Auslöser: PR aktualisiert die OAuth-Integration für Google Sign-In.
Claude Code findet: Die Token-Aktualisierungslogik sieht korrekt aus. Die Bereiche sind ordnungsgemäß konfiguriert.
Sai findet: Nach der Anmeldung bei Google landet die Weiterleitung auf einer 404-Seite, da die Rückruf-URL im Code, aber nicht in der Google Cloud Console-Konfiguration aktualisiert wurde.
Ergebnis: Sai macht Screenshots von der 404. Das Team aktualisiert die Google Cloud Console. Sai testet erneut den gesamten OAuth-Ablauf — Anmeldung, Weiterleitung, Sitzungserstellung — und bestätigt, dass er durchgängig funktioniert.
Szenario 4: Reproduzieren eines Benutzerfehlerberichts anhand eines Screenshots
Auslöser: Ein Nutzer veröffentlicht einen Screenshot in Slack: „Diese Seite sieht kaputt aus.“
Claude Code allein: Ein Screenshot kann nicht verarbeitet werden. Benötigt Codekontext.
Sagte: Öffnet dieselbe Seite, identifiziert das defekte Layout und klickt sich durch, um den genauen Status zu reproduzieren. Generiert die Schritte zur Reproduktion mit drei kommentierten Screenshots. Übergibt Claude Code die Dateipfade, die Seiten-URL und das erwartete Verhalten im Vergleich zum tatsächlichen Verhalten.
Ergebnis: Claude Code identifiziert einen Z-Index-Konflikt in einer kürzlich zusammengeführten PR. Behebt ihn. Sai überprüft, ob die Seite korrekt gerendert wird.
Szenario 5: API-Änderung unterbricht das Frontend stillschweigend
Auslöser: Backend-PR ändert die Antwortform von /api/orders — benennt um total_betrag zu Gesamtbetrag.
Claude Code findet: Die API-Änderung entspricht der neuen Namenskonvention. Die Backend-Tests bestehen.
Sai findet: Auf der Frontend-Bestellhistorie-Seite wird für jede Bestellsumme „$NaN“ angezeigt. Der Frontend-Code verweist immer noch total_betrag.
Ergebnis: Sai macht einen Screenshot der defekten Bestellhistorie. Claude Code findet die Frontend-Referenz und aktualisiert sie. Sai testet die Seite mit dem Bestellverlauf erneut mit echten Daten.
Stop doing repetitive tasks. Let Sai handle them for you.
Sai is your AI computer use agent — it operates your apps, automates your workflows, and gets work done while you focus on what matters.


.svg)

.svg)