
おっと!フォームの送信中に問題が発生しました。

OpenAI CodexとClaude Codeは、現在入手可能な2つの最も有能な自律型コーディングエージェントです。どちらも同じことを約束します。つまり、必要なものを自然言語で記述し、エージェントがコードの記述、編集、テストを行います。
しかし、彼らは根本的に異なる方向からこの約束に取り組んでいます。
コーデックス クラウドで実行されます。ChatGPT インターフェイスまたは API を介してタスクを送信すると、そのタスクはサンドボックス環境内で実行されます。つまり、リポジトリを読み込んだり、コードを記述したり、テストを実行したり、完了したプルリクエストを返したりします。その動作は見ていません。終了したら結果を見直します。
クロード・コード ターミナルで実行されます。コマンドを入力すると、ローカルマシン上のタスク (ファイルの読み取り、変更、テストスイートの実行、リポジトリへの直接コミット) を実行します。すべてのステップをリアルタイムで確認することも、そのまま終了させることもできます。
このアーキテクチャ上の違い (クラウドサンドボックスとローカルターミナル) が、速度、コスト、セキュリティ、ワークフロー統合、各ツールが適切に処理するタスクの種類など、すべてを形作っています。
私たちは3週間かけて両方のエージェントをプロダクションプロジェクトで使い、重要な違いを見つけました。このガイドでは、アーキテクチャ、コード品質、理由、価格設定、開発者エクスペリエンス、そしてどちらのツールでも埋められない重大なギャップなど、あらゆる側面を網羅しています。
オープンAIコーデックス は、2025年5月に発売されたクラウドベースのコーディングエージェントです。ChatGPT プラットフォームに組み込まれており、ソフトウェアエンジニアリングタスク専用に微調整された o3 のバージョンである codex-1 モデルを使用しています。
仕組み:
ChatGPT インターフェースを介して GitHub リポジトリを Codex に接続します。次に、タスクを記述します。
"Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API documentation."
次に、コーデックス:
すべてのプロセスはクラウドで非同期的に行われます。ブラウザを閉じたり、タブを切り替えたり、複数のタスクを並行して送信したりできます。各タスクにはそれぞれ独立したサンドボックスがあり、デフォルトではインターネットアクセスは無効になっています。
主な特徴:

クロード・コード はAnthropicのターミナルベースのコーディングエージェントで、2025年2月にリサーチプレビューとして発売され、2025年5月から一般公開されています。クロード・ソネット 4 をデフォルトモデルとして使用しており、オプションでクロード・オーパスを設定することもできます。
仕組み:
任意のプロジェクトディレクトリでターミナルを開き、次のように入力します クロード、そしてあなたのタスクを説明してください:
claude "Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API docs."
それではクロード・コード:
すべてがマシン、ターミナルで行われます。エージェントが考えたり、ファイルを読んだり、コードを記述したり、テストを実行したりするのがリアルタイムでわかります。いつでも中断、リダイレクト、フォローアップの質問をすることができます。
主な特徴:
これが根本的な違いです。他のすべての区別は、このアーキテクチャの選択から生じます。
コーデックスは デリゲーション・アンド・フォーゲット・モデル。タスクを送信します。クラウドで実行されます。結果を確認します。
ワークフロー:
このモデルの利点:
デメリット:
クロード・コードは以下で動作します インタラクティブ・オートノミー・モデル。自律的に動作しますが、あなたが監視している状態で、あなたのマシン上で動作します。
ワークフロー:
クロード プロジェクトディレクトリにこのモデルの利点:
デメリット:
コーデックス ソフトウェアエンジニアリング用に微調整されたOpenAIのo3モデルのバージョンであるcodex-1を使用しています。o3 ベースは強い論理的推論を可能にし、微調整によってコードベースの読み込み、コーディング規約の順守、プロダクション品質の実装の生成に最適化されます。
クロード・コード デフォルトではクロード・ソネット4を使用し、クロード・オーパスのオプション設定も可能です。クロードのモデルは、注意深く推論し、指示に従い、長い文脈を理解することで知られています。
ベンチマークの比較では、どちらのモデルも標準のコーディングタスクで同様のレベルで機能します。SWE-Benchの結果は競争力のあるスコアを示しています。実際の違いは未加工モデルの機能ではなく、各ツールがその機能をどのように適用するかにあります。
クロード・コード 行動する前にもっと深く推理する傾向があります。最初の試行では、より多くのファイルを読み込み、より多くのエッジケースを考慮し、アーキテクチャ的に考え抜かれたソリューションを生成します。私たちのテストでは、Claude Code のほうが、複雑な複数ファイルのタスクを本番環境ですぐに使える結果にたどり着くまでに必要な反復回数が少なくなりました。
コーデックス 明確に定義され、スコープが設定されたタスクほど実行速度が速くなる傾向があります。クラウドサンドボックスはすぐに起動し、o3 バックボーンは単純な実装タスクを効率的に処理します。「このエンドポイントを追加」や「このモジュールのテストを書く」といったタスクでは、Claude Code が同じ作業をローカルで完了するよりも Codex の方が結果を返すのが早いことがよくあります。
どちらのツールも複数ファイルの変更を処理しますが、アプローチは異なります。
Builder.ioの分析によると、クロード・コードは約 5.5倍少ないトークン 同等のタスクを実行する同等のツールよりも優れています。これは部分的にはアーキテクチャ上のもので、Claude Codeのプランニング優先のアプローチではやりとりが減り、一部はモデルレベルであり、Claudeのモデルの推論チェーンはより簡潔になっています。
CodexのトークンはChatGPTサブスクリプションにバンドルされているため、トークンの使用は透明性が低くなります。API を直接使用しない限り、タスクごとのトークン数は表示されません。
コーデックス ChatGPT Pro(月額200ドル)、チーム(ユーザーあたり月額30ドル)、およびエンタープライズプランに含まれています。プロユーザーには最も高いレート制限が適用され、チームユーザーには中程度のレート制限が適用されます。Codexには無料利用枠はありません。制限付きアクセスには、少なくともChatGPT Plusサブスクリプション(月額20ドル)が必要です。
バンドル価格モデルということは、他の理由ですでにChatGPT Proの料金を支払っている場合でも、Codexは事実上「無料」であることを意味します。しかし、Codex専用に購読している場合、月額200ドルは高額です。特に、ライトユーザーが月額50〜80ドルを費やす可能性のあるClaude Codeのトークンごとの価格と比較すると特にそうです。
クロード・コード BYOK(個人所有の鍵の持ち込み)モデルを使用しています。トークンごとに直接 Anthropic に支払います。
コーディングエージェントを断続的に使用する開発者にとって(毎日終日ではなく、1日に数回のタスク)、Claude Codeのトークンごとのモデルの方がはるかに安価です。コーディングエージェントを 1 日中継続的に実行している開発者にとって、コストは ChatGPT Pro の定額料金に近いと言えます。
どちらのツールもコードレビューを提供しますが、アプローチは異なります。
Codex は、「この PR にバグ、セキュリティ上の問題、スタイルの矛盾がないかを確認する」というタスクとして PR diff を送信することで、コードレビューに使用できます。サンドボックス内の差分を分析し、構造化されたフィードバックを返します。
Codex は非同期で実行されるため、Codex レビュー用に新しい PR を自動的に送信するワークフローを設定できます。結果はコメントまたは要約として返されます。
クロード・コードにはビルトインがあります /レビュー 自動PRレビュー用のコマンドとGitHubアクション。専用のサブエージェントを使用します。
サブエージェントアーキテクチャでは、より構造化され、分類された結果が得られます。各レビュー担当者は独立して業務を行うため、シングルパスレビューでは見落としがちな問題を見逃す可能性が低くなります。
実装が必要なGitHubの課題が10件ある場合、Codexでは10件すべてを同時に提出できます。各タスクには独自のサンドボックスが割り当てられ、結果は別々の PR として返されます。Claude Code はこれらを 1 つずつ順番に処理します。
明確に定義されたタスクのバックログが大量にあるチームにとって、この並列処理は変革をもたらします。1 日の朝分のタスク送信で、1 日分の PR を作成できます。
コーデックスは完全にクラウド上で動作します。アプリケーションの実行、デバッグ、ビデオ通話による会議への出席など、マシンは他の作業に自由に使えます。Claude Code は動作中にマシンの CPU、メモリ、ディスク I/O を消費します。
チームがすでに研究、文書化、ブレーンストーミング、コミュニケーションにChatGPTを使用している場合、Codexは同じインターフェースで機能します。コンテキストの切り替えは不要です。「このアルゴリズムの説明」から「コードベースへの実装」まで、1 つの会話で進めることができます。
各コーデックスタスクは、デフォルトではネットワークにアクセスできないサンドボックスコンテナで実行されます。エージェントがプロジェクト外のファイルを誤って変更したり、破壊的なコマンドを実行したり、ローカルの機密データにアクセスしたりするリスクはゼロです。Claude Code はユーザーの権限でユーザーのマシン上で実行されます。タスクの設定を誤ると、理論的にはローカルに損害を与える可能性があります (ただし、Anthropic には保護手段があります)。
Codex はブランチを作成し、プルリクエストを直接オープンします。出力されるのは、説明、変更、テスト結果を含む、すぐに人間が確認できる PR です。Claude Code はローカルでコミットし、ユーザーは手動でプッシュします (またはプッシュするように設定します)。
複雑なコードベースの理解、アーキテクチャ上の決定による推論、多数のファイルにわたる一貫した変更の生成を必要とするタスクでは、Claude Codeの方が常に優れています。その計画優先のアプローチとサブエージェントアーキテクチャは、あいまいさをより適切に処理します。
私たちのテストでは、クロード・コードが作成されました 最初の試行で本番環境ですぐに結果が出る 10 個以上のファイル、なじみのないコードベース、または要件があいまいなタスクでは、Codex よりも頻繁に使用されます。
タスクがあいまいな場合や、実行の途中でアプローチが間違っていることに気付いた場合は、Claude Code ですぐに介入できます。「やめて、新しいレートリミッターを書く代わりに既存のレートリミッターを使え」と言うと、調整されます。Codex では、結果を待ってから却下し、明確な指示に従って再送信します。
Claude Code は、ローカルデータベース、Docker コンテナ、環境変数、API キー、および内部ツールを使用します。テストで実行中の PostgreSQL インスタンスが必要な場合、Claude Code はマシンですでに実行されているインスタンスに接続します。Codex のサンドボックスにはアクセスできません。
これは次の場合に最も重要です。
Claude Codeは、タスクごとに使用するトークンが約5.5倍少なく、各タスクのコストを正確に表示します。プロンプトの最適化、モデル選択の調整 (Sonnet vs Opus)、支出の正確な管理が可能です。Codexの費用はサブスクリプションの中に隠されています。
Claude Codeは、SSHセッション、CIパイプライン、Dockerコンテナ、クラウドVMなど、あらゆるターミナルで動作します。スクリプトで自動化し、ビルドシステムに統合できます。Codex には ChatGPT インターフェースまたは API が必要ですが、既存の自動化に組み込むのは困難です。
コードはマシンに残ります。Anthropic の API に送信されて処理されますが、クラウドサンドボックスに保存されたり、ChatGPT アカウントに関連付けられたりすることはありません。厳格なデータポリシー、SOC 2 要件、または機密コードベースを持つ企業にとって、これは重要です。
これは、他の「コーデックスとクロードコード」の比較ではスキップされるセクションです。
どちらのツールもコードエージェントです。ソースコードを読み取り、実装を生成し、テストスイートを実行します。どちらでもありません:
コーデックスとクロードコードはどちらもコードレイヤーで動作します。コードがコンパイルされ、リンティングに合格し、既存のテストに合格することを検証します。コードが正しいユーザーエクスペリエンスを生み出すかどうかは検証しません。
実際の例: PR は割引計算ロジックを更新します。両方のエージェントが差分を確認したところ、問題は見つかりませんでした。計算は正しく、テストは合格です。しかし、ユーザーがクーポンを適用し、アイテムを削除してからチェックアウトに進むと、合計がマイナスになります。どちらの関数のコードにもバグはありません。これは 2 つのフロー間の相互作用にあります。実際に実行中のアプリケーションをテストして初めて検出できます。
3週間のテストでは、約 本番環境に達したバグの 35-40% コーデックスもクロード・コードも検出できなかったカテゴリに分類されました。視覚的なリグレッション、クロスフロー状態のバグ、環境固有の障害などです。
サイは AI エージェントです クラウドデスクトップで動作します。ブラウザを実行し、スクリーンショットを撮り、エラーログを読み取り、デプロイされたアプリケーションとやりとりします。これは、CodexとClaude Codeの両方にない検証レイヤーです。
SaiのクラウドデスクトップでClaude Codeとペアリングした場合これにより、完全なビルドテスト修正ループが作成されます。
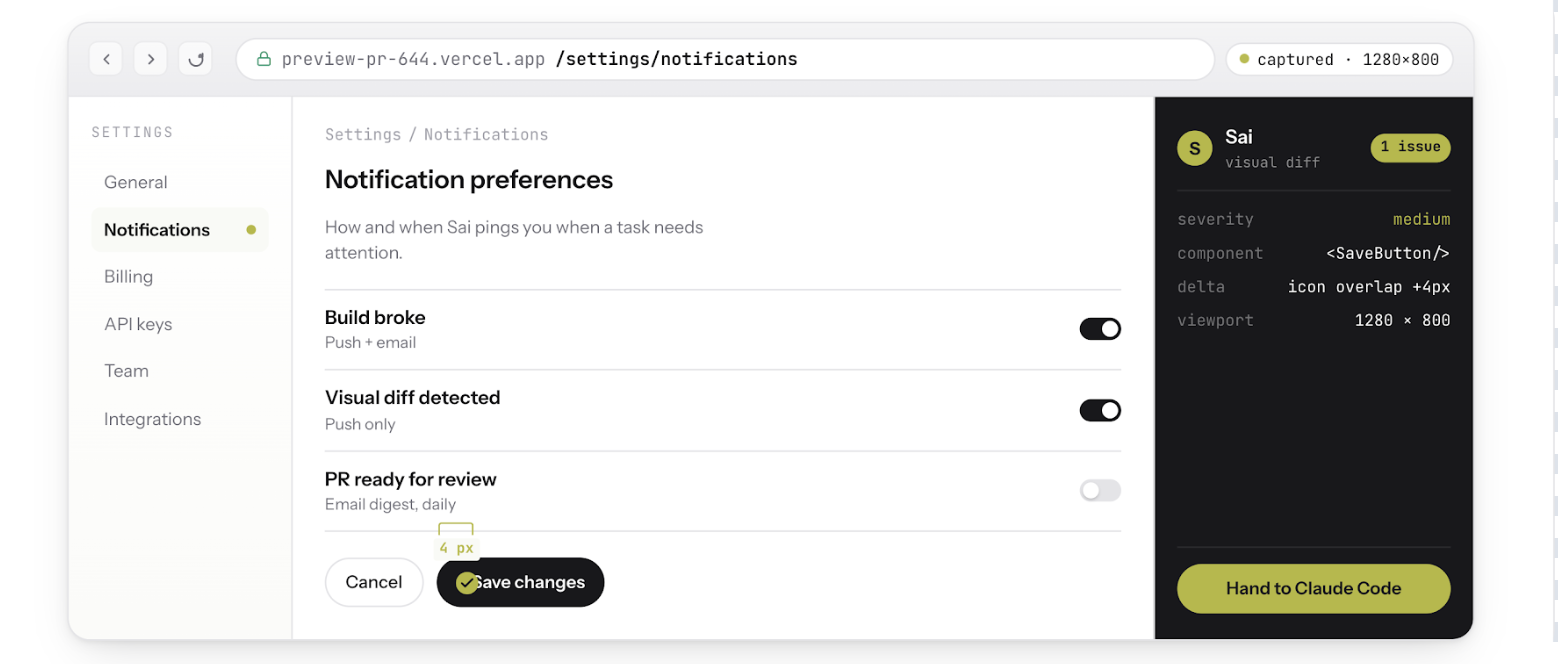
コーデックスとクロード・コードだけでは、ステップ2から5までを実行することはできません。どちらも「コードがコンパイルされ、テストに合格する」というところで終わります。Sai は停止したところから立ち上がり、実際の製品を検証します。
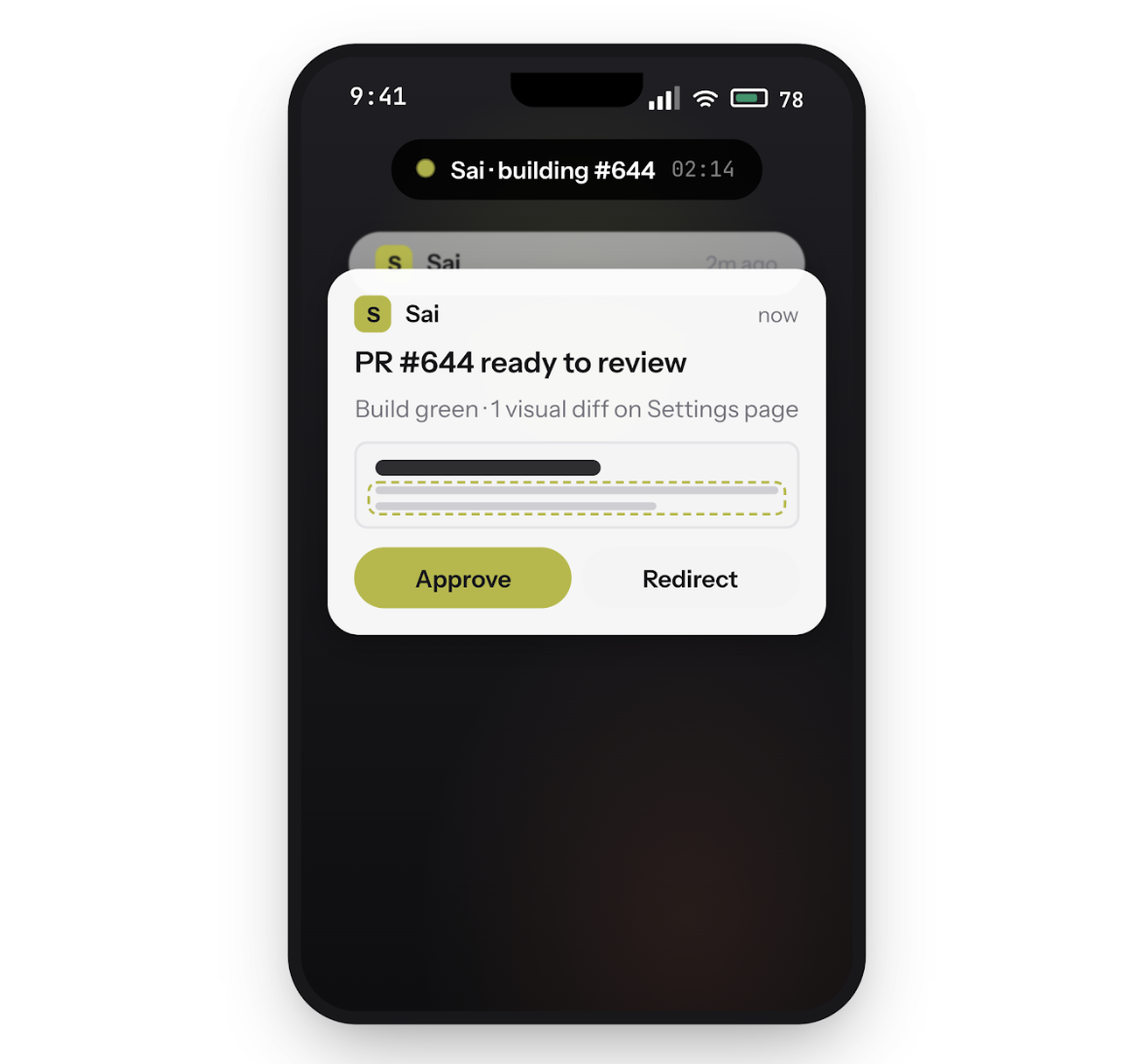
SaiのクラウドデスクトップでClaude Codeを実行し、ラップトップを閉じます。コーディングエージェントは、あなたが離れている間も、ビルド、テスト、コミットといった作業を続けます。アクションの承認、タスクのリダイレクト、修正プログラムの送信など、スマートフォンからループをどこからでも操作できます。
PR が開くと、Sai はプレビューデプロイを開いてテストアカウントでログインし、影響を受けるユーザーフローをクリックします。すべての状態遷移のスクリーンショットを撮り、コードレビューでは検出できない視覚的なリグレッション、壊れたフロー、状態依存のバグにフラグを立てます。
ユーザーのバグスクリーンショットを Sai に貼り付けます。アプリを調査し、問題を引き起こした一連のアクションを正確に再現し、再現手順、予想される動作と実際の動作、注釈付きのスクリーンショットを含む構造化されたレポートをClaude Codeに渡します。