
Oups ! Une erreur s'est produite lors de l'envoi du formulaire.

OpenAI Codex et Claude Code sont les deux agents de codage autonomes les plus performants disponibles aujourd'hui. Les deux promettent la même chose : décrivez ce que vous voulez en langage naturel, et l'agent écrit, édite et teste le code pour vous.
Mais ils abordent cette promesse dans des directions fondamentalement différentes.
Codex fonctionne dans le cloud. Vous soumettez une tâche via l'interface ou l'API ChatGPT, et elle s'exécute dans un environnement sandbox : lecture de votre référentiel, écriture de code, exécution de tests et renvoi d'une pull request terminée. Vous ne le regardez pas fonctionner. Vous vérifiez le résultat lorsqu'il est terminé.
Claude Code s'exécute dans votre terminal. Vous tapez une commande qui exécute la tâche sur votre machine locale : lire vos fichiers, apporter des modifications, exécuter votre suite de tests et valider directement dans votre référentiel. Vous pouvez suivre chaque étape en temps réel ou vous en aller et la laisser se terminer.
Cette différence architecturale (sandbox cloud par rapport à terminal local) influence tout : rapidité, coût, sécurité, intégration des flux de travail et types de tâches que chaque outil gère bien.
Nous avons passé trois semaines à utiliser les deux agents sur des projets de production afin de trouver les véritables différences qui comptent. Ce guide couvre tous les aspects : l'architecture, la qualité du code, le raisonnement, la tarification, l'expérience des développeurs et la lacune critique qu'aucun outil ne comble.
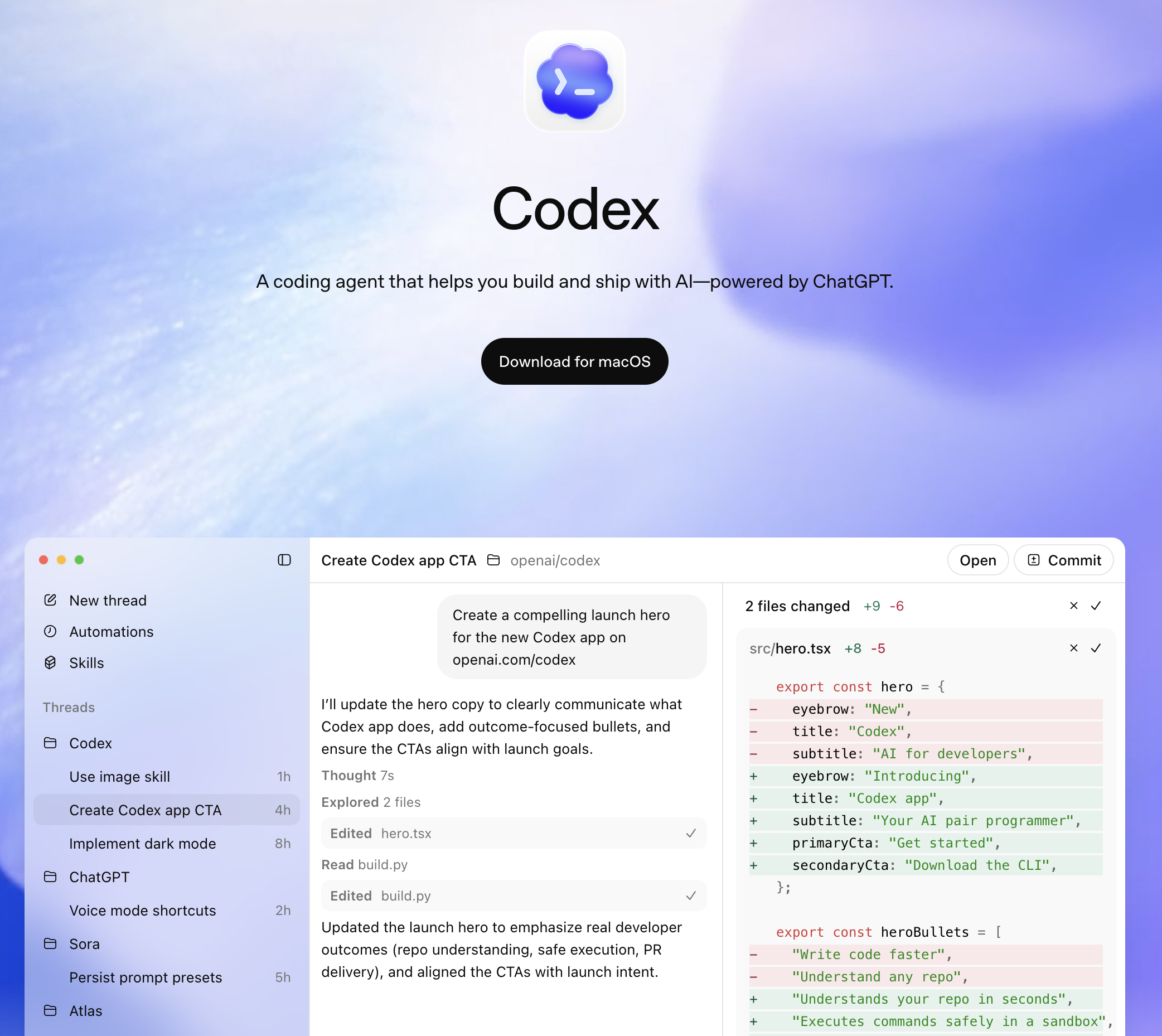
Codex OpenAI est un agent de codage basé sur le cloud lancé en mai 2025. Il est intégré à la plateforme ChatGPT et utilise le modèle codex-1, qui est une version de o3 spécialement adaptée aux tâches de génie logiciel.
Comment ça fonctionne :
Vous connectez votre dépôt GitHub au Codex via l'interface ChatGPT. Vous décrivez ensuite une tâche :
"Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API documentation."
Codex puis :
L'ensemble du processus se déroule de manière asynchrone dans le cloud. Vous pouvez fermer votre navigateur, changer d'onglet ou soumettre plusieurs tâches en parallèle. Chaque tâche dispose de son propre sandbox isolé, l'accès à Internet étant désactivé par défaut.
Caractéristiques principales :

Claude Code est l'agent de codage basé sur les terminaux d'Anthropic, lancé en tant qu'aperçu de recherche en février 2025 et généralement disponible depuis mai 2025. Il utilise Claude Sonnet 4 comme modèle par défaut avec la possibilité de configurer Claude Opus.
Comment ça fonctionne :
Vous ouvrez votre terminal dans n'importe quel répertoire de projet, tapez claude, et décrivez votre tâche :
claude "Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API docs."
Claude Code puis :
Tout se passe sur votre machine, dans votre terminal. Vous pouvez voir l'agent réfléchir, lire des fichiers, écrire du code et exécuter des tests en temps réel. Vous pouvez interrompre, rediriger ou poser des questions complémentaires à tout moment.
Caractéristiques principales :
C'est là la différence fondamentale. Toutes les autres distinctions découlent de ce choix architectural.
Le Codex fonctionne sur un modèle de délégation et d'oubli. Vous soumettez une tâche. Il fonctionne dans le cloud. Vous examinez le résultat.
Le flux de travail :
Les avantages de ce modèle :
Inconvénients :
Claude Code fonctionne sur un modèle d'autonomie interactive. Il fonctionne de manière autonome mais sur votre machine, sous votre surveillance.
Le flux de travail :
claude dans le répertoire de votre projetLes avantages de ce modèle :
Inconvénients :
Codex utilise codex-1, une version du modèle o3 d'OpenAI adaptée au génie logiciel. La base o3 lui confère un raisonnement logique solide, et les ajustements l'optimisent pour lire les bases de code, suivre les conventions de codage et générer des implémentations de qualité de production.
Claude Code utilise Claude Sonnet 4 par défaut, avec une configuration optionnelle pour Claude Opus. Les modèles de Claude sont connus pour leur raisonnement minutieux, leur suivi des instructions et leur compréhension du contexte à long terme.
Dans les comparaisons de référence, les deux modèles fonctionnent à des niveaux similaires pour les tâches de codage standard. Les résultats du SWE-bench montrent des scores compétitifs. La différence pratique ne réside pas dans la capacité du modèle brut, mais dans la manière dont chaque outil applique cette capacité.
Claude Code a tendance à raisonner plus profondément avant d'agir. Il lit plus de fichiers, prend en compte davantage de cas extrêmes et produit des solutions plus réfléchies sur le plan architectural dès la première tentative. Lors de nos tests, Claude Code a nécessité moins d'itérations pour obtenir un résultat prêt pour la production pour les tâches complexes comportant plusieurs fichiers.
Codex a tendance à s'exécuter plus rapidement pour des tâches bien définies et délimitées. Son sandbox cloud fonctionne rapidement et le backbone o3 gère efficacement les tâches de mise en œuvre simples. Pour des tâches telles que « ajouter ce point de terminaison » ou « écrire des tests pour ce module », Codex renvoie souvent un résultat plus rapidement que Claude Code n'effectue le même travail localement.
Les deux outils gèrent les modifications de plusieurs fichiers, mais les approches diffèrent :
L'analyse de Builder.io a révélé que Claude Code utilise environ 5,5 fois moins de jetons par rapport à des outils comparables pour des tâches équivalentes. C'est en partie architectural (l'approche de planification d'abord de Claude Code réduit les allers-retours) et en partie au niveau des modèles, les modèles de Claude étant plus concis dans leurs chaînes de raisonnement.
L'utilisation des jetons par le Codex est moins transparente car elle est intégrée à l'abonnement ChatGPT. Le nombre de jetons par tâche ne s'affiche pas, sauf si vous utilisez directement l'API.
Codex est inclus dans les forfaits ChatGPT Pro (200 $/mois), Team (30 $/utilisateur/mois) et Enterprise. Les utilisateurs Pro bénéficient des limites de débit les plus élevées, tandis que les utilisateurs Team bénéficient d'une utilisation modérée. Il n'y a pas de niveau gratuit pour Codex. Vous avez besoin d'au moins un abonnement ChatGPT Plus (20$ par mois) pour un accès limité.
Le modèle de tarification groupé signifie que Codex est effectivement « gratuit » si vous payez déjà pour ChatGPT Pro pour d'autres raisons. Mais si vous vous abonnez spécifiquement à Codex, 200 dollars par mois, c'est élevé, surtout par rapport à la tarification par jeton de Claude Code, où les utilisateurs légers peuvent dépenser 50 à 80 dollars par mois.
Claude Code utilise un modèle BYOK (apportez votre propre clé). Vous payez Anthropic directement par jeton :
Pour les développeurs qui utilisent des agents de codage par intermittence (quelques tâches par jour, pas toute la journée), le modèle par jeton de Claude Code est nettement moins cher. Pour les développeurs qui utilisent des agents de codage en permanence tout au long de la journée, le coût est proche du tarif forfaitaire de ChatGPT Pro.
Les deux outils proposent une révision du code, mais avec des approches différentes.
Le Codex peut être utilisé pour la révision du code en soumettant un différentiel de relations publiques sous la forme d'une tâche : « Vérifiez ce PR pour détecter les bogues, les problèmes de sécurité et les incohérences de style ». Il analyse les différences dans son bac à sable et renvoie un feedback structuré.
Comme le Codex fonctionne de manière asynchrone, vous pouvez configurer des flux de travail qui soumettent automatiquement les nouveaux PR pour révision du Codex. Les résultats sont renvoyés sous forme de commentaires ou de résumé.
Claude Code possède une fonction intégrée /critique commande et une action GitHub pour une révision automatique des relations publiques. Il utilise des sous-agents spécialisés :
L'architecture des sous-agents produit des résultats plus structurés et classés. Chaque réviseur agit de manière indépendante, ce qui réduit le risque de passer à côté de problèmes qu'une évaluation en un seul passage pourrait ignorer.
Si vous rencontrez 10 problèmes GitHub qui doivent être mis en œuvre, Codex vous permet de les soumettre simultanément. Chaque tâche dispose de son propre bac à sable et les résultats sont renvoyés sous forme de PR distincts. Claude Code les gère de manière séquentielle, une à la fois.
Pour les équipes qui ont d'importants arriérés de tâches bien définies, ce parallélisme est transformateur. Une matinée de soumissions de tâches peut produire l'équivalent d'une journée de relations publiques.
Le Codex fonctionne entièrement dans le cloud. Votre machine reste libre pour d'autres tâches, comme l'exécution de l'application, le débogage, la participation à des réunions lors d'appels vidéo. Claude Code consomme le processeur, la mémoire et les E/S disque de votre machine pendant qu'elle fonctionne.
Si votre équipe utilise déjà ChatGPT pour la recherche, la documentation, le brainstorming et la communication, Codex se trouve dans la même interface. Pas de changement de contexte. Vous pouvez passer de « expliquer cet algorithme » à « l'implémenter dans notre base de code » en une seule conversation.
Chaque tâche du Codex s'exécute dans un conteneur sandbox sans accès réseau par défaut. Il n'y a aucun risque que l'agent modifie accidentellement des fichiers en dehors du projet, exécute des commandes destructrices ou accède à des données locales sensibles. Claude Code s'exécute sur votre machine avec vos autorisations. Une tâche mal configurée pourrait théoriquement provoquer des dommages locaux (bien qu'Anthropic dispose de garanties).
Le Codex crée des succursales et ouvre directement des pull requests. Le résultat est un PR prêt à être examiné par un humain, avec une description, les modifications et les résultats des tests. Claude Code commite localement et vous pouvez lancer le push manuellement (ou le configurer pour le push).
Pour les tâches qui nécessitent de comprendre des bases de code complexes, de raisonner en fonction de décisions architecturales et de produire des modifications cohérentes dans de nombreux fichiers, Claude Code est toujours plus performant. Son approche axée sur la planification et son architecture de sous-agents permettent de mieux gérer l'ambiguïté.
Lors de nos tests, Claude Code a produit des résultats prêts pour la production dès la première tentative plus souvent que Codex pour les tâches impliquant plus de 10 fichiers, des bases de code inconnues ou des exigences ambiguës.
Lorsqu'une tâche est ambiguë ou que vous vous rendez compte en cours d'exécution que l'approche est erronée, Claude Code vous permet d'intervenir immédiatement. Dites « Arrêtez, utilisez le limiteur de débit existant au lieu d'en écrire un nouveau » et il s'ajuste. Avec Codex, vous attendez le résultat, vous le rejetez et vous le soumettez à nouveau avec des instructions clarifiées.
Claude Code utilise vos bases de données locales, vos conteneurs Docker, vos variables d'environnement, vos clés d'API et vos outils internes. Si vos tests nécessitent une instance de PostgreSQL en cours d'exécution, Claude Code se connecte à celle qui est déjà en cours d'exécution sur votre machine. Le bac à sable du Codex ne peut pas y accéder.
Cela est particulièrement important pour :
Claude Code utilise environ 5,5 fois moins de jetons par tâche et vous indique exactement le coût de chaque tâche. Vous pouvez optimiser les instructions, ajuster la sélection du modèle (Sonnet ou Opus) et contrôler les dépenses avec précision. Les coûts du Codex sont cachés dans l'abonnement.
Claude Code s'exécute dans n'importe quel terminal : sessions SSH, pipelines CI, conteneurs Docker, machines virtuelles cloud. Vous pouvez l'automatiser dans des scripts et l'intégrer dans les systèmes de build. Le Codex nécessite l'interface ou l'API ChatGPT, qui est plus difficile à intégrer dans l'automatisation existante.
Votre code reste sur votre machine. Il est envoyé à l'API d'Anthropic pour traitement mais n'est pas stocké dans un sandbox cloud ni associé à un compte ChatGPT. Pour les entreprises qui appliquent des politiques strictes en matière de données, des exigences SOC 2 ou des bases de code classifiées, c'est important.
Voici la section que toutes les autres comparaisons « Codex vs Claude Code » ignorent.
Les deux outils sont des agents de code. Ils lisent le code source, génèrent des implémentations et exécutent des suites de tests. Ni l'un ni l'autre :
Codex et Claude Code fonctionnent tous deux dans la couche de code. Ils vérifient que le code est compilé, passe avec succès le linting et passe les tests existants. Ils ne vérifient pas si le code produit une expérience utilisateur correcte.
Exemple concret : Un PR met à jour la logique de calcul des remises. Les deux agents examinent la différence et ne trouvent aucun problème : les calculs sont corrects, les tests sont réussis. Mais lorsqu'un utilisateur applique un coupon, supprime un article, puis passe à la caisse, le total devient négatif. Le bogue ne se trouve pas dans le code de l'une ou l'autre des fonctions. C'est dans l'interaction entre deux flux. Seul le test de l'application en cours d'exécution permet de le détecter.
Au cours de notre test de trois semaines, environ 35 à 40 % des bugs arrivés en production appartenaient à des catégories que ni le Codex ni Claude Code ne pouvaient détecter, à savoir les régressions visuelles, les bogues d'état des flux croisés et les défaillances spécifiques à l'environnement.
Sai est un agent d'IA qui fonctionne sur un poste de travail dans le cloud. Il exécute les navigateurs, prend des captures d'écran, lit les journaux d'erreurs et interagit avec les applications déployées : la couche de vérification qui fait défaut au Codex et à Claude Code.
Lorsqu'il est associé à Claude Code sur le bureau cloud de Sai, il crée une boucle build-test-fix complète :
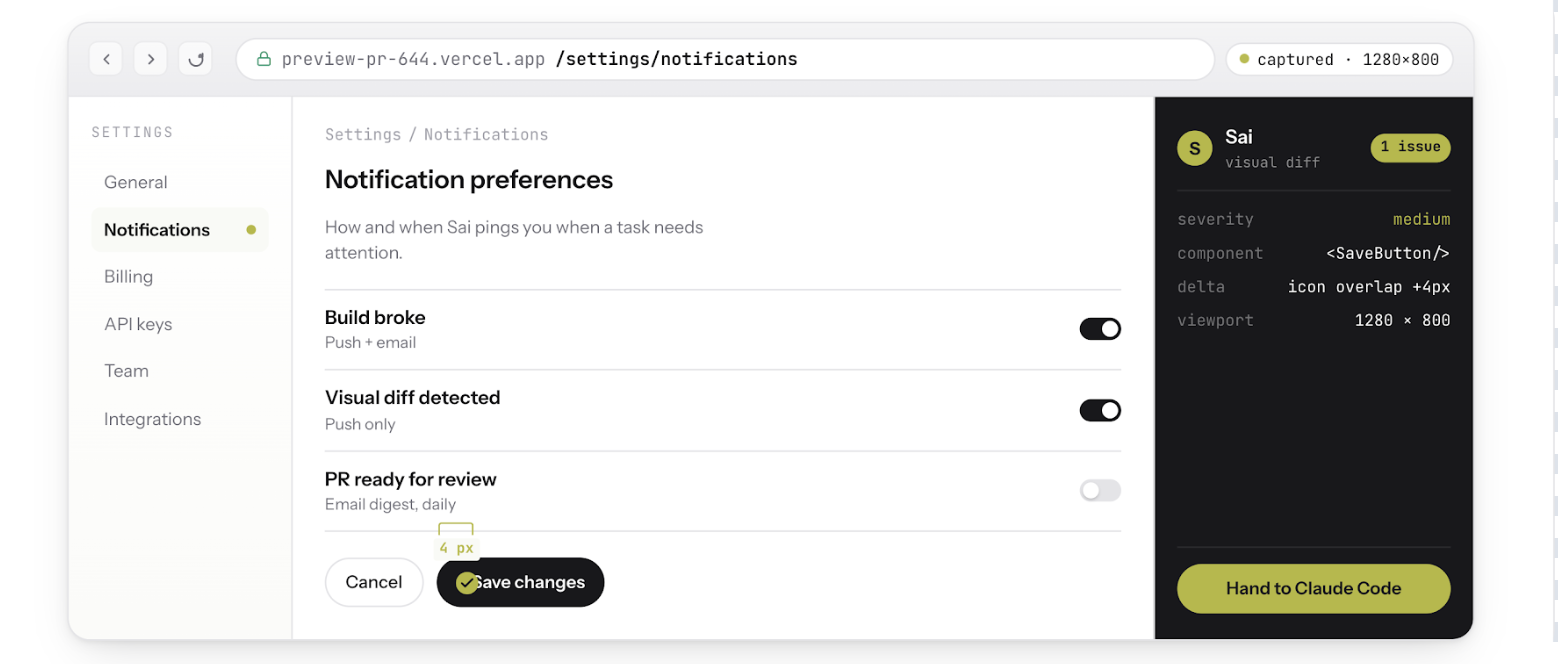
Ni le Codex ni Claude Code ne peuvent à eux seuls effectuer les étapes 2 à 5. Ils s'arrêtent tous les deux à « le code est compilé et les tests réussissent ». Sai reprend là où ils s'arrêtent et vérifie le produit réel.
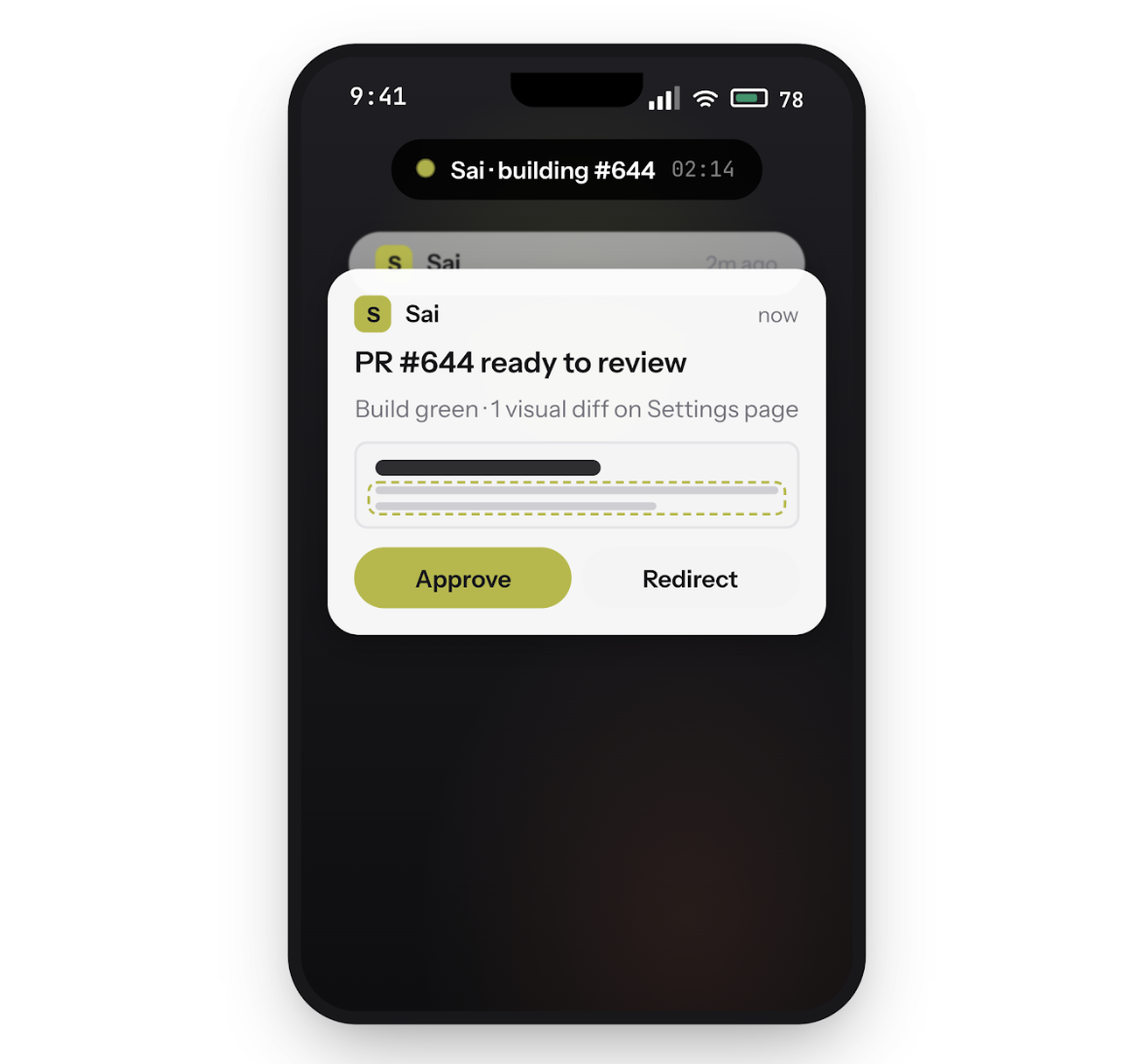
Exécutez Claude Code sur le bureau cloud de Sai et fermez votre ordinateur portable. Votre agent de codage continue de travailler (création, test, validation) pendant que vous vous éloignez. Dirigez la boucle depuis votre téléphone : approuvez des actions, redirigez des tâches ou envoyez un correctif où que vous soyez.
Lorsqu'un PR s'ouvre, Sai ouvre votre déploiement d'aperçu, se connecte avec un compte de test et clique sur les flux d'utilisateurs concernés. Il capture chaque transition d'état et signale les régressions visuelles, les flux interrompus et les bogues dépendant de l'état que la revue de code ne peut pas détecter.
Collez la capture d'écran du bogue d'un utilisateur dans Sai. Il explore votre application, reproduit la séquence exacte des actions à l'origine du problème et transmet à Claude Code un rapport structuré comprenant les étapes à suivre pour reproduire, le comportement attendu et le comportement réel, ainsi que des captures d'écran annotées.