
Hoppla! Beim Absenden des Formulars ist etwas schief gelaufen.

OpenAI Codex und Claude Code sind die beiden leistungsfähigsten autonomen Codierungsagenten, die heute erhältlich sind. Beide versprechen dasselbe: Beschreiben Sie in natürlicher Sprache, was Sie wollen, und der Agent schreibt, bearbeitet und testet den Code für Sie.
Aber sie nähern sich diesem Versprechen aus grundlegend unterschiedlichen Richtungen.
Kodex läuft in der Cloud. Sie reichen eine Aufgabe über die ChatGPT-Schnittstelle oder API ein und sie wird in einer Sandbox-Umgebung ausgeführt. Dabei wird Ihr Repository gelesen, Code geschrieben, Tests ausgeführt und eine abgeschlossene Pull-Anfrage zurückgegeben. Du siehst nicht zu, wie es funktioniert. Sie überprüfen das Ergebnis, wenn es fertig ist.
Claude Codex läuft in deinem Terminal. Sie geben einen Befehl ein und dieser erledigt die Aufgabe auf Ihrem lokalen Computer — Sie lesen Ihre Dateien, nehmen Änderungen vor, führen Ihre Testsuite aus und übertragen sich direkt in Ihr Projektarchiv. Sie können jeden Schritt in Echtzeit verfolgen oder einfach weggehen und den Vorgang abschließen lassen.
Dieser architektonische Unterschied — Cloud-Sandbox versus lokales Terminal — bestimmt alles: Geschwindigkeit, Kosten, Sicherheit, Workflow-Integration und die Art der Aufgaben, die jedes Tool gut bewältigt.
Wir haben drei Wochen damit verbracht, beide Agenten für Produktionsprojekte einzusetzen, um die wirklichen Unterschiede herauszufinden, auf die es ankommt. Dieser Leitfaden deckt alle Aspekte ab: Architektur, Codequalität, Argumentation, Preisgestaltung, Entwicklererfahrung und die kritische Lücke, die keines der Tools schließt.
OpenAI-Kodex ist ein Cloud-basierter Codierungsagent, der im Mai 2025 auf den Markt gebracht wurde. Es ist in die ChatGPT-Plattform integriert und verwendet das Codex-1-Modell, eine Version von o3, die speziell für Softwareentwicklungsaufgaben optimiert wurde.
So funktioniert's:
Du verbindest dein GitHub-Repository über die ChatGPT-Schnittstelle mit Codex. Dann beschreibst du eine Aufgabe:
"Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API documentation."
Codex dann:
Der gesamte Prozess findet asynchron in der Cloud statt. Sie können Ihren Browser schließen, zwischen Tabs wechseln oder mehrere Aufgaben parallel einreichen. Jede Aufgabe erhält ihre eigene isolierte Sandbox, in der der Internetzugang standardmäßig deaktiviert ist.
Die wichtigsten Eigenschaften:

Claude Codex ist der terminalbasierte Codierungsagent von Anthropic, der im Februar 2025 als Forschungsvorschau auf den Markt gebracht wurde und seit Mai 2025 allgemein verfügbar ist. Es verwendet Claude Sonnet 4 als Standardmodell mit der Option, Claude Opus zu konfigurieren.
So funktioniert's:
Sie öffnen Ihr Terminal in einem beliebigen Projektverzeichnis, geben Sie ein Claude, und beschreibe deine Aufgabe:
claude "Add rate limiting to the /api/users endpoint. Use Redis for the token bucket.
Include tests and update the API docs."
Claude Code dann:
Alles passiert auf Ihrem Computer, in Ihrem Terminal. Sie sehen, wie der Agent denkt, Dateien liest, Code schreibt und Tests in Echtzeit ausführt. Sie können jederzeit unterbrechen, umleiten oder Folgefragen stellen.
Die wichtigsten Eigenschaften:
Das ist der grundlegende Unterschied. Jeder andere Unterschied ergibt sich aus dieser architektonischen Wahl.
Codex arbeitet auf einer Modell „Delegieren und Vergessen“. Sie reichen eine Aufgabe ein. Sie läuft in der Cloud. Sie überprüfen das Ergebnis.
Der Arbeitsablauf:
Vorteile dieses Modells:
Nachteile:
Claude Code operiert auf einem interaktives Autonomiemodell. Es funktioniert autonom, aber auf Ihrem Computer, während Sie zuschauen.
Der Arbeitsablauf:
Claude in Ihrem ProjektverzeichnisVorteile dieses Modells:
Nachteile:
Kodex verwendet Codex-1, eine Version des o3-Modells von OpenAI, die für die Softwareentwicklung optimiert ist. Die o3-Basis liefert starke logische Überlegungen, und die Feinabstimmung optimiert sie für das Lesen von Codebasen, die Einhaltung von Codierungskonventionen und die Generierung von Implementierungen in Produktionsqualität.
Claude Codex verwendet standardmäßig Claude Sonnet 4, mit optionaler Konfiguration für Claude Opus. Claudes Modelle sind dafür bekannt, sorgfältig zu denken, Anweisungen zu befolgen und lange Zusammenhänge zu verstehen.
In Benchmark-Vergleichen schneiden beide Modelle bei Standard-Codierungsaufgaben auf ähnlichem Niveau ab. Die Ergebnisse von SWE-Bench zeigen wettbewerbsfähige Ergebnisse. Der praktische Unterschied besteht nicht in der Fähigkeit des Rohmodells, sondern darin, wie jedes Tool diese Fähigkeit anwendet.
Claude Codex neigt dazu, gründlicher zu überlegen, bevor man handelt. Es liest mehr Dateien, berücksichtigt mehr Randfälle und liefert beim ersten Versuch architektonisch durchdachtere Lösungen. In unseren Tests benötigte Claude Code weniger Iterationen, um bei komplexen, aus mehreren Dateien bestehenden Aufgaben ein produktionsreifes Ergebnis zu erzielen.
Kodex neigt dazu, bei genau definierten Aufgaben mit einem bestimmten Umfang schneller ausgeführt zu werden. Die Cloud-Sandbox läuft schnell und das o3-Backbone erledigt einfache Implementierungsaufgaben effizient. Bei Aufgaben wie „Diesen Endpunkt hinzufügen“ oder „Tests für dieses Modul schreiben“ gibt Codex oft schneller ein Ergebnis zurück, als Claude Code dieselbe Arbeit lokal erledigt.
Beide Tools verarbeiten Änderungen an mehreren Dateien, aber die Herangehensweisen unterscheiden sich:
Die Analyse von Builder.io ergab, dass Claude Code ungefähr verwendet 5.5x weniger Token als vergleichbare Tools für gleichwertige Aufgaben. Das ist teilweise architektonisch — Claude Codes Ansatz, bei dem die Planung an erster Stelle steht, reduziert das Hin und Her — und teilweise auf Modellebene, wobei Claudes Modelle in ihren Argumentationsketten prägnanter sind.
Die Token-Nutzung von Codex ist weniger transparent, da sie im ChatGPT-Abonnement enthalten ist. Sie sehen keine Token-Anzahl pro Aufgabe, es sei denn, Sie verwenden die API direkt.
Kodex ist in den Plänen ChatGPT Pro (200 USD/Monat), Team (30 USD/Benutzer/Monat) und Enterprise enthalten. Pro-Benutzer erhalten die höchsten Ratenlimits, während Team-Benutzer nur mäßig genutzt werden. Es gibt keine kostenlose Stufe für Codex — du benötigst mindestens ein ChatGPT Plus-Abonnement (20 $/Monat) für eingeschränkten Zugriff.
Das gebündelte Preismodell bedeutet, dass Codex effektiv „kostenlos“ ist, wenn Sie aus anderen Gründen bereits für ChatGPT Pro bezahlen. Aber wenn du speziell Codex abonnierst, sind 200 $/Monat ziemlich hoch — vor allem im Vergleich zu Claude Codes Preisen pro Token, wo Light-Nutzer 50-80 $/Monat ausgeben könnten.
Claude Codex verwendet ein BYOK-Modell (bring your own key). Sie zahlen Anthropic direkt pro Token:
Für Entwickler, die zeitweise Codierungsagenten verwenden — ein paar Aufgaben pro Tag, nicht jeden Tag den ganzen Tag — ist das Token-Modell von Claude Code deutlich günstiger. Für Entwickler, die den ganzen Tag über Programmieragenten verwenden, nähern sich die Kosten der Flatrate von ChatGPT Pro.
Beide Tools bieten Code-Reviews an, jedoch mit unterschiedlichen Ansätzen.
Codex kann für Code-Reviews verwendet werden, indem ein PR-Diff als Aufgabe eingereicht wird: „Überprüfe diese PR auf Fehler, Sicherheitsprobleme und Stilinkonsistenzen.“ Es analysiert den Unterschied in seiner Sandbox und gibt strukturiertes Feedback zurück.
Da Codex asynchron läuft, können Sie Workflows einrichten, die automatisch neue PRs zur Codex-Überprüfung einreichen. Die Ergebnisse werden als Kommentare oder als Zusammenfassung zurückgegeben.
Claude Code hat eine eingebaute /rezension Befehl und eine GitHub-Aktion für eine automatisierte PR-Überprüfung. Es verwendet spezialisierte Subagenten:
Die Subagenten-Architektur liefert strukturiertere, kategorisiertere Ergebnisse. Jeder Prüfer arbeitet unabhängig, wodurch die Wahrscheinlichkeit verringert wird, dass Probleme übersehen werden, die bei einer Prüfung in einem Durchgang übersehen werden könnten.
Wenn Sie 10 GitHub-Probleme haben, die implementiert werden müssen, können Sie mit Codex alle 10 gleichzeitig einreichen. Jede Aufgabe erhält ihre eigene Sandbox und die Ergebnisse werden als separate PRs zurückgegeben. Claude Code behandelt diese nacheinander — eins nach dem anderen.
Für Teams mit einem großen Rückstand an klar definierten Aufgaben ist diese Parallelität transformativ. Das Einreichen von Aufgaben an einem Morgen kann zu PRs für einen ganzen Tag führen.
Codex läuft vollständig in der Cloud. Ihr Computer bleibt für andere Arbeiten frei — zum Ausführen der Anwendung, zum Debuggen, zur Teilnahme an Besprechungen per Videoanruf. Claude Code verbraucht CPU, Arbeitsspeicher und Festplatten-I/O auf Ihrem Computer, während er arbeitet.
Wenn Ihr Team ChatGPT bereits für Recherche, Dokumentation, Brainstorming und Kommunikation verwendet, verwendet Codex dieselbe Oberfläche. Kein Kontextwechsel. Sie können in einer Konversation von „Erkläre diesen Algorithmus“ zu „Implementieren Sie ihn in unserer Codebasis“ übergehen.
Jede Codex-Aufgabe wird standardmäßig in einem Sandbox-Container ohne Netzwerkzugriff ausgeführt. Es besteht kein Risiko, dass der Agent versehentlich Dateien außerhalb des Projekts ändert, destruktive Befehle ausführt oder auf sensible lokale Daten zugreift. Claude Code wird auf Ihrem Computer mit Ihren Berechtigungen ausgeführt. Eine falsch konfigurierte Aufgabe könnte theoretisch lokale Schäden verursachen (obwohl Anthropic über Sicherheitsvorkehrungen verfügt).
Codex erstellt Branches und öffnet direkt Pull-Requests. Das Ergebnis ist eine PR, die zur menschlichen Überprüfung bereit ist — mit einer Beschreibung, den Änderungen und den Testergebnissen. Claude Code schreibt lokal fest und Sie pushen manuell (oder konfigurieren es für Push).
Bei Aufgaben, bei denen es darum geht, komplexe Codebasen zu verstehen, architektonische Entscheidungen zu durchdenken und kohärente Änderungen in vielen Dateien vorzunehmen, übertrifft Claude Code durchweg die Nase. Sein Ansatz, bei dem die Planung an erster Stelle steht, und die Subagenten-Architektur gehen besser mit Mehrdeutigkeiten um.
In unseren Tests produzierte Claude Code produktionsreife Ergebnisse auf Anhieb häufiger als Codex für Aufgaben mit mehr als 10 Dateien, unbekannten Codebasen oder mehrdeutigen Anforderungen.
Wenn eine Aufgabe mehrdeutig ist oder Sie während der Ausführung feststellen, dass der Ansatz falsch ist, können Sie mit Claude Code sofort eingreifen. Sagen Sie „Stopp — verwenden Sie den vorhandenen Ratenbegrenzer, anstatt einen neuen zu schreiben“, und schon passt er sich an. Bei Codex warten Sie auf das Ergebnis, lehnen es ab und reichen es mit klaren Anweisungen erneut ein.
Claude Code verwendet Ihre lokalen Datenbanken, Docker-Container, Umgebungsvariablen, API-Schlüssel und interne Tools. Wenn Ihre Tests eine laufende PostgreSQL-Instanz erfordern, stellt Claude Code eine Verbindung zu der Instanz her, die bereits auf Ihrem Computer ausgeführt wird. Die Sandbox von Codex kann es nicht erreichen.
Das ist am wichtigsten für:
Claude Code verwendet ungefähr 5,5x weniger Token pro Aufgabe und zeigt Ihnen genau, was jede Aufgabe kostet. Sie können die Eingabeaufforderungen optimieren, die Modellauswahl anpassen (Sonnet im Vergleich zu Opus) und die Ausgaben präzise kontrollieren. Die Kosten von Codex sind im Abonnement versteckt.
Claude Code läuft auf jedem Terminal — SSH-Sitzungen, CI-Pipelines, Docker-Container, Cloud-VMs. Sie können es in Skripten automatisieren und in Build-Systeme integrieren. Codex benötigt die ChatGPT-Schnittstelle oder API, die sich schwieriger in die bestehende Automatisierung einbetten lässt.
Ihr Code bleibt auf Ihrem Gerät. Er wird zur Verarbeitung an die API von Anthropic gesendet, aber nicht in einer Cloud-Sandbox gespeichert oder mit einem ChatGPT-Konto verknüpft. Für Unternehmen mit strengen Datenrichtlinien, SOC 2-Anforderungen oder klassifizierten Codebasen ist dies wichtig.
Hier ist der Abschnitt, den jeder andere Vergleich zwischen „Codex und Claude Code“ überspringt.
Beide Tools sind Code-Agenten. Sie lesen Quellcode, generieren Implementierungen und führen Testsuiten aus. Keiner von beiden:
Sowohl Codex als auch Claude Code arbeiten in der Codeebene. Sie überprüfen, ob der Code kompiliert wird, Linting besteht und bestehende Tests besteht. Sie überprüfen nicht, ob der Code die richtige Benutzererfahrung bietet.
Echtes Beispiel: Ein PR aktualisiert die Logik der Rabattberechnung. Beide Agenten überprüfen den Unterschied und finden keine Probleme — die Mathematik ist korrekt, die Tests bestehen. Wenn ein Benutzer jedoch einen Gutschein einlöst, einen Artikel entfernt und dann zur Kasse geht, wird die Gesamtsumme negativ. Der Fehler ist nicht im Code einer der beiden Funktionen enthalten. Es liegt in der Interaktion zwischen zwei Flüssen. Nur beim Testen der tatsächlich laufenden Anwendung wird der Fehler erkannt.
In unserem dreiwöchigen Test waren es ungefähr 35-40% der Bugs, die die Produktion erreichten waren in Kategorien unterteilt, die weder Codex noch Claude Code erkennen konnten — visuelle Regressionen, Cross-Flow-State-Bugs und umgebungsspezifische Fehler.
Sai ist ein KI-Agent das läuft auf einem Cloud-Desktop. Es führt Browser aus, macht Screenshots, liest Fehlerprotokolle und interagiert mit bereitgestellten Anwendungen — die Verifizierungsebene, die sowohl Codex als auch Claude Code fehlt.
Bei Kopplung mit Claude Code auf Sais Cloud-Desktop, es erstellt eine komplette Build-Test-Fix-Schleife:
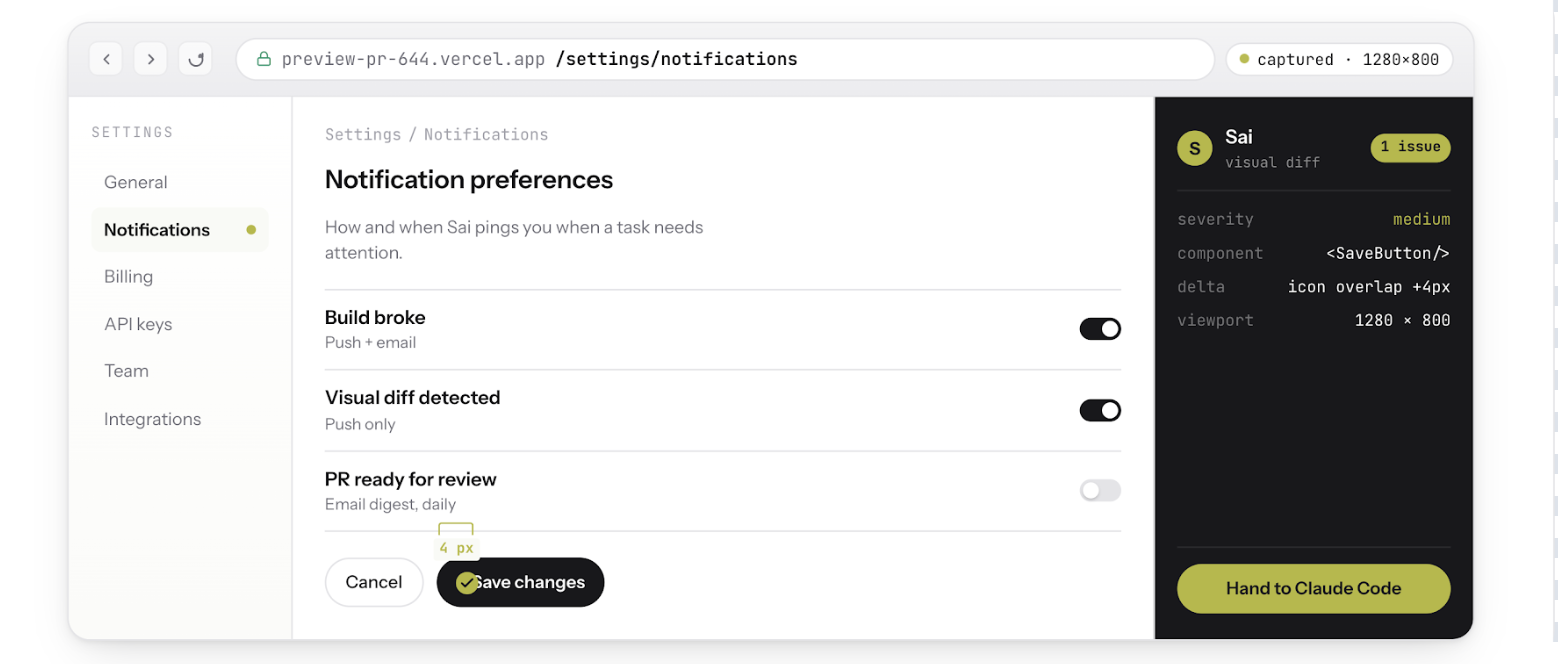
Weder Codex noch Claude Code alleine können die Schritte 2 bis 5 ausführen. Beide hören bei „Der Code wird kompiliert und die Tests bestanden“ auf. Sai macht da weiter, wo sie aufhören, und verifiziert das eigentliche Produkt.
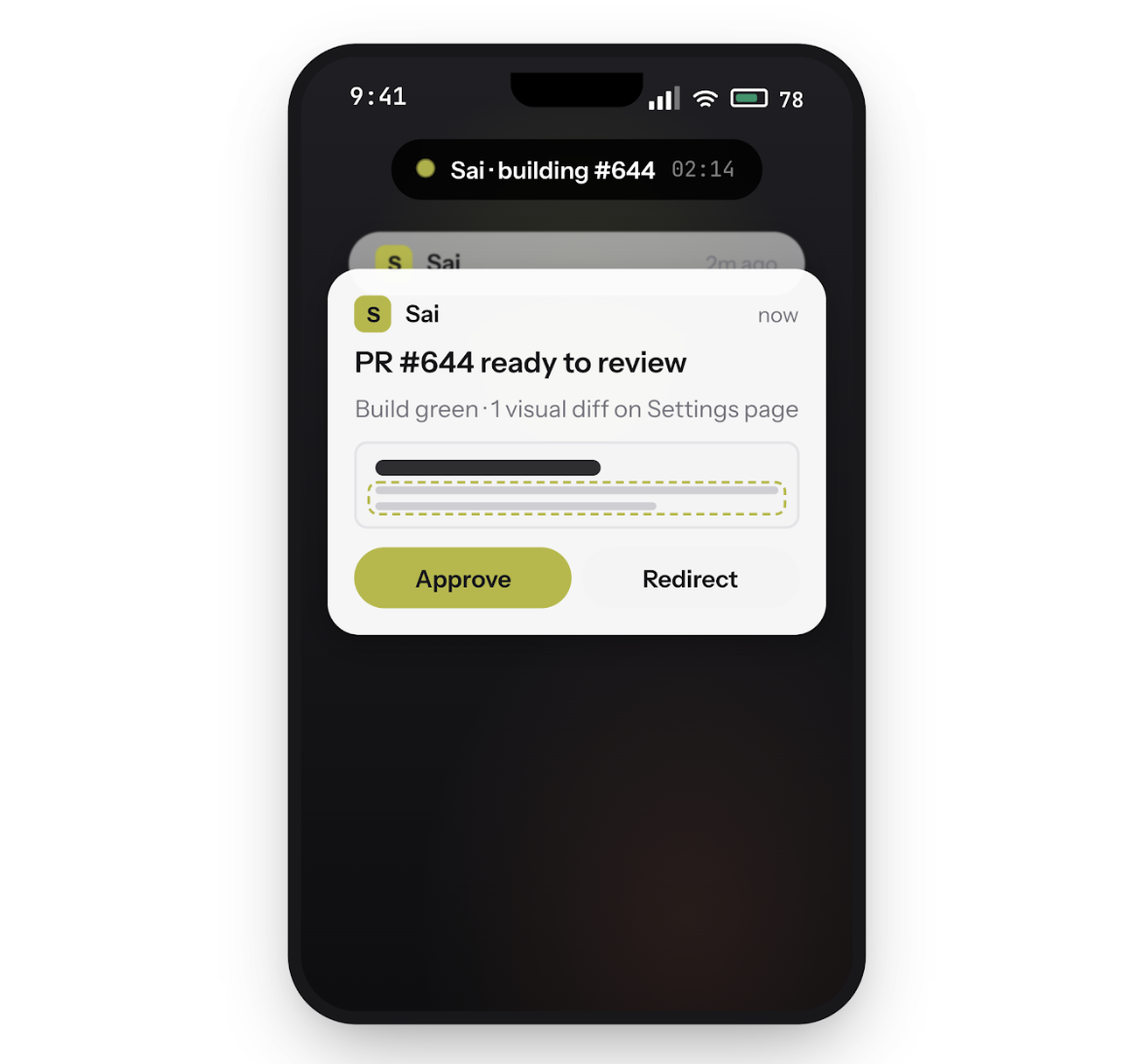
Führen Sie Claude Code auf Sais Cloud-Desktop aus und schließen Sie Ihren Laptop. Ihr Coding-Agent arbeitet weiter — erstellt, testet, bestätigt — während Sie weggehen. Steuern Sie den Kreislauf von Ihrem Telefon aus: Genehmigen Sie Aktionen, leiten Sie Aufgaben um oder versenden Sie eine Problembehebung von überall aus.
Wenn eine PR geöffnet wird, öffnet Sai Ihre Vorschaubereitstellung, meldet sich mit einem Testkonto an und klickt sich durch die betroffenen Benutzerabläufe. Es zeigt jeden Zustandsübergang und kennzeichnet visuelle Regressionen, unterbrochene Abläufe und zustandsabhängige Fehler, die durch Code-Reviews nicht auffangen können.
Fügen Sie den Bug-Screenshot eines Benutzers in Sai ein. Es untersucht Ihre App, reproduziert die genaue Abfolge der Aktionen, die das Problem ausgelöst haben, und übergibt Claude Code einen strukturierten Bericht mit Schritten zur Reproduktion, erwartetem Verhalten und kommentierten Screenshots.